DeepSeek v3-Funktionen
Entdecken Sie die beeindruckenden Funktionen von DeepSeek v3 in verschiedenen Bereichen – von komplexen Überlegungen bis hin zur Codegenerierung
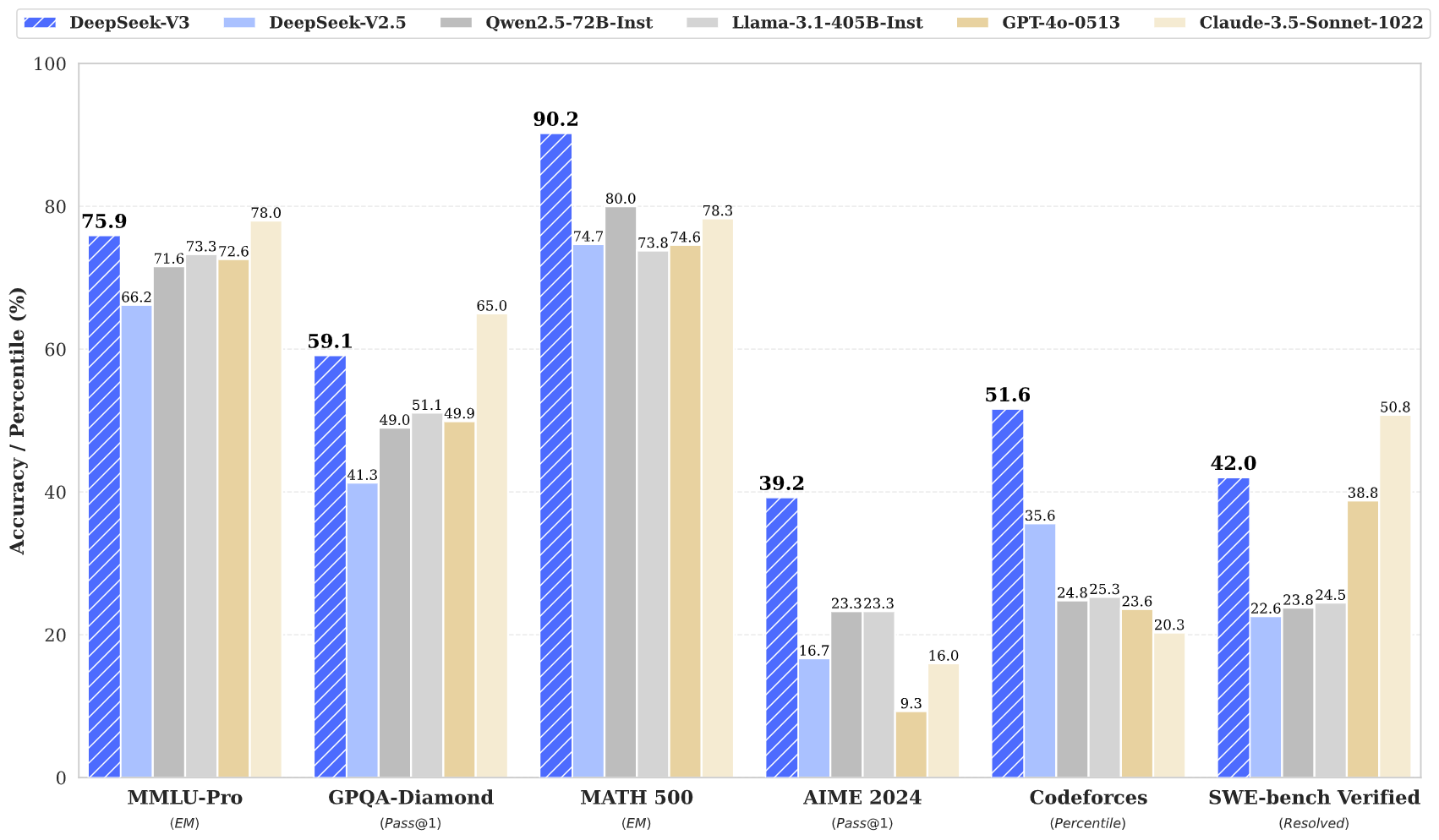

DeepSeek v3 stellt einen großen Durchbruch bei KI-Sprachmodellen dar und verfügt über insgesamt 671 Milliarden Parameter, von denen 37 Milliarden für jedes Token aktiviert sind. DeepSeek v3 basiert auf der innovativen Mixture-of-Experts-Architektur (MoE) und bietet hochmoderne Leistung über verschiedene Benchmarks hinweg bei gleichzeitiger Beibehaltung einer effizienten Inferenz.
Entdecken Sie die beeindruckenden Funktionen von DeepSeek v3 in verschiedenen Bereichen – von komplexen Überlegungen bis hin zur Codegenerierung
Entdecken Sie, was DeepSeek v3 zur ersten Wahl bei großen Sprachmodellen macht
DeepSeek v3 nutzt eine innovative Mixture-of-Experts-Architektur mit 671B Gesamtparametern und aktiviert 37B Parameter für jeden Token für optimale Leistung.
DeepSeek v3 ist auf 14,8 Billionen hochwertige Token vorab trainiert und demonstriert umfassendes Wissen in verschiedenen Bereichen.
DeepSeek v3 erzielt hochmoderne Ergebnisse bei mehreren Benchmarks, darunter Mathematik, Codierung und mehrsprachige Aufgaben.
Trotz seiner Größe behält DeepSeek v3 durch innovatives Architekturdesign effiziente Inferenzfunktionen bei.
Mit einem 128K-Kontextfenster kann DeepSeek v3 umfangreiche Eingabesequenzen effektiv verarbeiten und verstehen.
DeepSeek v3 enthält eine erweiterte Multi-Token-Vorhersage für verbesserte Leistung und Inferenzbeschleunigung.
Greifen Sie in drei einfachen Schritten auf die Leistungsfähigkeit von DeepSeek v3 zu
Wählen Sie aus verschiedenen Aufgaben aus, darunter Textgenerierung, Code-Vervollständigung und mathematisches Denken. DeepSeek v3 zeichnet sich über mehrere Domänen hinweg aus.
Geben Sie Ihre Aufforderung oder Frage ein. Die fortschrittliche Architektur von DeepSeek v3 gewährleistet mit seinem 671B-Parametermodell qualitativ hochwertige Antworten.
Erleben Sie die überlegene Leistung von DeepSeek v3 mit Antworten, die fortgeschrittenes Denken und Verständnis demonstrieren.
Entdecken Sie, wie DeepSeek v3 den Bereich der KI-Sprachmodelle vorantreibt
Bleiben Sie mit den neuesten Nachrichten und Erkenntnissen aus DeepSeek v3 auf dem Laufenden

DeepSeek V3.1 – Umfassende Analyse des neuesten Open-Source-AI-Modells

DeepSeek‑V3‑0324 – Umfassende Verbesserungen über alle Fähigkeiten hinweg

DeepSeek V3 – Neue Maßstäbe für Effizienz in der KI
DeepSeek v3 stellt die neueste Weiterentwicklung bei großen Sprachmodellen dar und verfügt über eine bahnbrechende Mixture-of-Experts-Architektur mit insgesamt 671 Milliarden Parametern. Dieses innovative Modell zeigt außergewöhnliche Leistung bei verschiedenen Benchmarks, darunter Mathematik, Codierung und mehrsprachige Aufgaben.
DeepSeek v3 basiert auf 14,8 Billionen verschiedenen Token und integriert fortschrittliche Techniken wie die Multi-Token-Vorhersage und setzt neue Maßstäbe in der KI-Sprachmodellierung. Das Modell unterstützt ein 128K-Kontextfenster und bietet eine mit führenden Closed-Source-Modellen vergleichbare Leistung bei gleichzeitiger Beibehaltung effizienter Inferenzfunktionen.
DeepSeek v3 kombiniert eine riesige 671B-Parameter-MoE-Architektur mit innovativen Funktionen wie Multi-Token-Vorhersage und verlustfreiem Lastausgleich und liefert so eine außergewöhnliche Leistung bei verschiedenen Aufgaben.
DeepSeek v3 ist über unsere Online-Demoplattform und API-Dienste verfügbar. Sie können die Modellgewichte auch für die lokale Bereitstellung herunterladen.
DeepSeek v3 zeigt überlegene Leistungen in den Bereichen Mathematik, Codierung, logisches Denken und mehrsprachige Aufgaben und erzielt bei Benchmark-Bewertungen durchweg Spitzenergebnisse.
DeepSeek v3 unterstützt verschiedene Bereitstellungsoptionen, darunter NVIDIA-GPUs, AMD-GPUs und Huawei Ascend NPUs, mit mehreren Framework-Optionen für optimale Leistung.
Ja, DeepSeek v3 unterstützt die kommerzielle Nutzung vorbehaltlich der Musterlizenzbedingungen.
DeepSeek v3 übertrifft andere Open-Source-Modelle und erreicht in verschiedenen Benchmarks eine Leistung, die mit führenden Closed-Source-Modellen vergleichbar ist.
DeepSeek v3 kann mit mehreren Frameworks bereitgestellt werden, darunter SGLang, LMDeploy, TensorRT-LLM, vLLM, und unterstützt sowohl den FP8- als auch den BF16-Inferenzmodus.
DeepSeek v3 verfügt über ein 128K-Kontextfenster, das es ihm ermöglicht, umfangreiche Eingabesequenzen für komplexe Aufgaben und lange Inhalte effektiv zu verarbeiten und zu verstehen.
DeepSeek v3 wurde auf 14,8 Billionen verschiedenen und hochwertigen Token vorab trainiert, gefolgt von überwachten Feinabstimmungs- und Reinforcement-Learning-Phasen. Der Trainingsprozess war bemerkenswert stabil und es gab keine unwiederbringlichen Verlustspitzen.
DeepSeek v3 nutzt FP8-Training mit gemischter Präzision und erreicht ein effizientes knotenübergreifendes MoE-Training durch Algorithmus-Framework-Hardware-Co-Design, wobei das Vortraining mit nur 2,788 Mio. H800-GPU-Stunden abgeschlossen wird.