Kemampuan DeepSeek v3
Jelajahi kemampuan mengesankan DeepSeek v3 di berbagai bidang - dari penalaran kompleks hingga pembuatan kode

DeepSeek v3 merupakan terobosan besar dalam model bahasa AI, dengan total 671B parameter dengan 37B diaktifkan untuk setiap token. Dibangun dengan arsitektur Mixture-of-Experts (MoE) yang inovatif, DeepSeek v3 memberikan kinerja mutakhir di berbagai tolok ukur sambil mempertahankan inferensi yang efisien.
Jelajahi kemampuan mengesankan DeepSeek v3 di berbagai bidang - dari penalaran kompleks hingga pembuatan kode
Temukan apa yang membuat DeepSeek v3 menjadi pilihan utama dalam model bahasa besar
DeepSeek v3 menggunakan arsitektur Mixture-of-Experts yang inovatif dengan total 671B parameter, mengaktifkan 37B parameter untuk setiap token untuk kinerja optimal.
Dilatih sebelumnya pada 14,8 triliun token berkualitas tinggi, DeepSeek v3 menunjukkan pengetahuan komprehensif di berbagai domain.
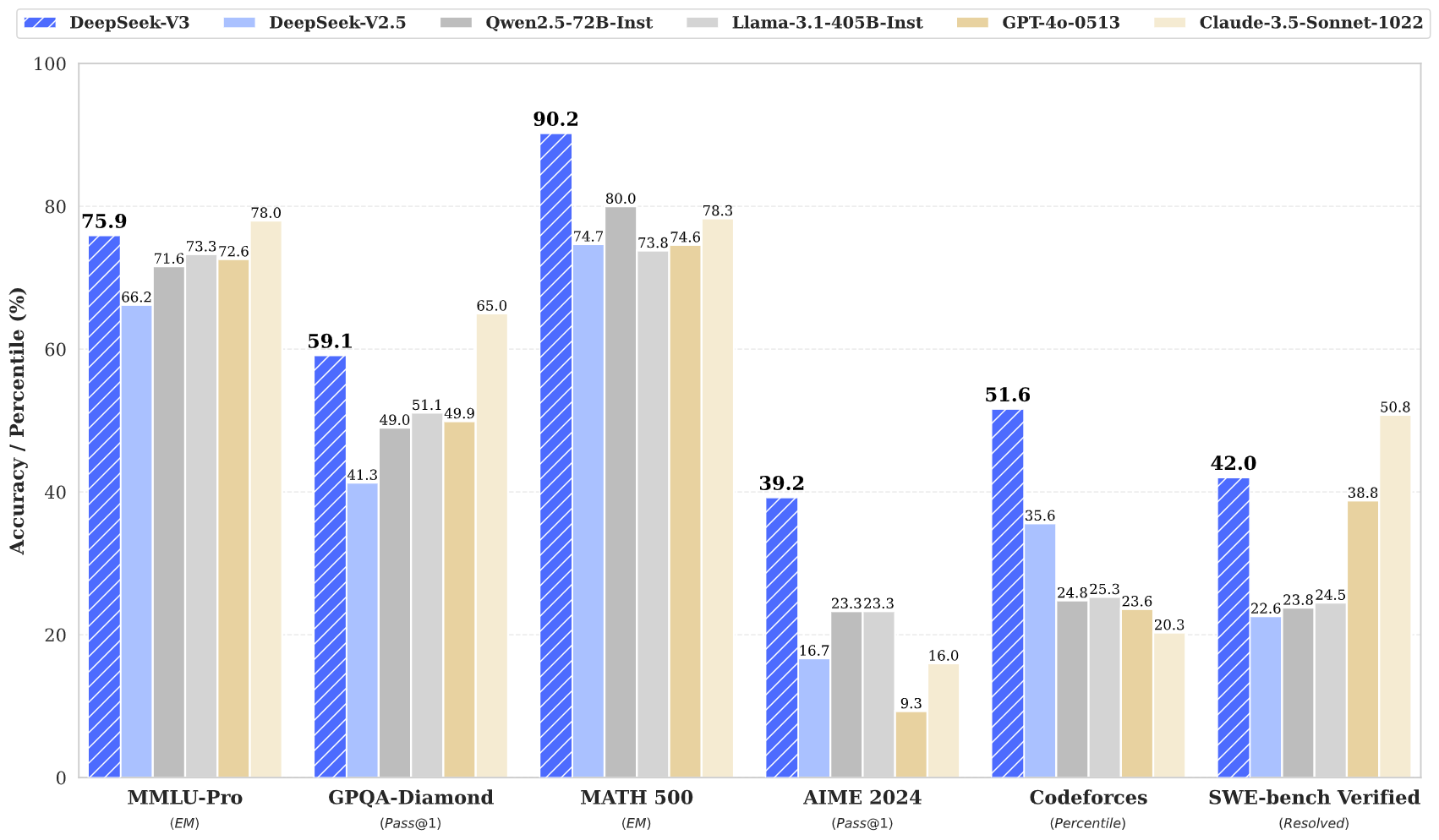
DeepSeek v3 mencapai hasil mutakhir di berbagai benchmark, termasuk matematika, pemrograman, dan tugas multibahasa.
Meskipun berukuran besar, DeepSeek v3 mempertahankan kemampuan inferensi yang efisien melalui desain arsitektur inovatif.
Dengan jendela konteks 128K, DeepSeek v3 dapat memproses dan memahami urutan input yang luas secara efektif.
DeepSeek v3 menggabungkan Prediksi Multi-Token canggih untuk peningkatan kinerja dan percepatan inferensi.
Akses kekuatan DeepSeek v3 dalam tiga langkah sederhana
Pilih dari berbagai tugas termasuk pembuatan teks, penyelesaian kode, dan penalaran matematis. DeepSeek v3 unggul di berbagai bidang.
Masukkan prompt atau pertanyaan Anda. Arsitektur canggih DeepSeek v3 memastikan respons berkualitas tinggi dengan model 671B parameternya.
Rasakan kinerja unggul DeepSeek v3 dengan respons yang menunjukkan penalaran dan pemahaman tingkat lanjut.
Temukan bagaimana DeepSeek v3 memajukan bidang model bahasa AI
Tetap update dengan berita dan wawasan terbaru dari DeepSeek v3

DeepSeek V3.1 — Analisis komprehensif model AI open source terbaru

DeepSeek‑V3‑0324 — Peningkatan komprehensif di semua kemampuan

DeepSeek V3 — Mendefinisikan ulang standar efisiensi AI
DeepSeek v3 merepresentasikan kemajuan terbaru dalam model bahasa besar, menampilkan arsitektur Mixture-of-Experts yang revolusioner dengan total 671B parameter. Model inovatif ini menunjukkan kinerja luar biasa di berbagai benchmark, termasuk matematika, pemrograman, dan tugas multibahasa.
Dilatih pada 14,8 triliun token beragam dan menggabungkan teknik canggih seperti Multi-Token Prediction, DeepSeek v3 menetapkan standar baru dalam pemodelan bahasa AI. Model ini mendukung jendela konteks 128K dan memberikan kinerja yang sebanding dengan model sumber tertutup terkemuka sambil mempertahankan kemampuan inferensi yang efisien.
DeepSeek v3 menggabungkan arsitektur MoE 671B parameter yang besar dengan fitur inovatif seperti Prediksi Multi-Token dan penyeimbangan beban bebas kerugian tambahan, memberikan kinerja luar biasa di berbagai tugas.
DeepSeek v3 tersedia melalui platform demo online dan layanan API kami. Anda juga dapat mengunduh bobot model untuk penerapan lokal.
DeepSeek v3 menunjukkan kinerja unggul dalam matematika, pemrograman, penalaran, dan tugas multibahasa, secara konsisten mencapai hasil teratas dalam evaluasi benchmark.
DeepSeek v3 mendukung berbagai opsi penerapan termasuk GPU NVIDIA, GPU AMD, dan NPU Huawei Ascend, dengan berbagai pilihan framework untuk kinerja optimal.
Ya, DeepSeek v3 mendukung penggunaan komersial sesuai dengan ketentuan lisensi model.
DeepSeek v3 mengungguli model sumber terbuka lainnya dan mencapai kinerja yang sebanding dengan model sumber tertutup terkemuka di berbagai benchmark.
DeepSeek v3 dapat diterapkan menggunakan beberapa framework termasuk SGLang, LMDeploy, TensorRT-LLM, vLLM, dan mendukung mode inferensi FP8 dan BF16.
DeepSeek v3 memiliki jendela konteks 128K, memungkinkannya untuk memproses dan memahami urutan input yang luas secara efektif untuk tugas kompleks dan konten panjang.
DeepSeek v3 dilatih sebelumnya pada 14,8 triliun token beragam dan berkualitas tinggi, diikuti dengan tahap Supervised Fine-Tuning dan Reinforcement Learning. Proses pelatihan sangat stabil tanpa lonjakan kerugian yang tidak dapat dipulihkan.
DeepSeek v3 menggunakan pelatihan presisi campuran FP8 dan mencapai pelatihan MoE lintas-node yang efisien melalui desain bersama algoritma-framework-hardware, menyelesaikan pra-pelatihan dengan hanya 2,788M jam GPU H800.