Capacidades do DeepSeek v3
Explore as impressionantes capacidades do DeepSeek v3 em diferentes domínios - do raciocínio complexo à geração de código
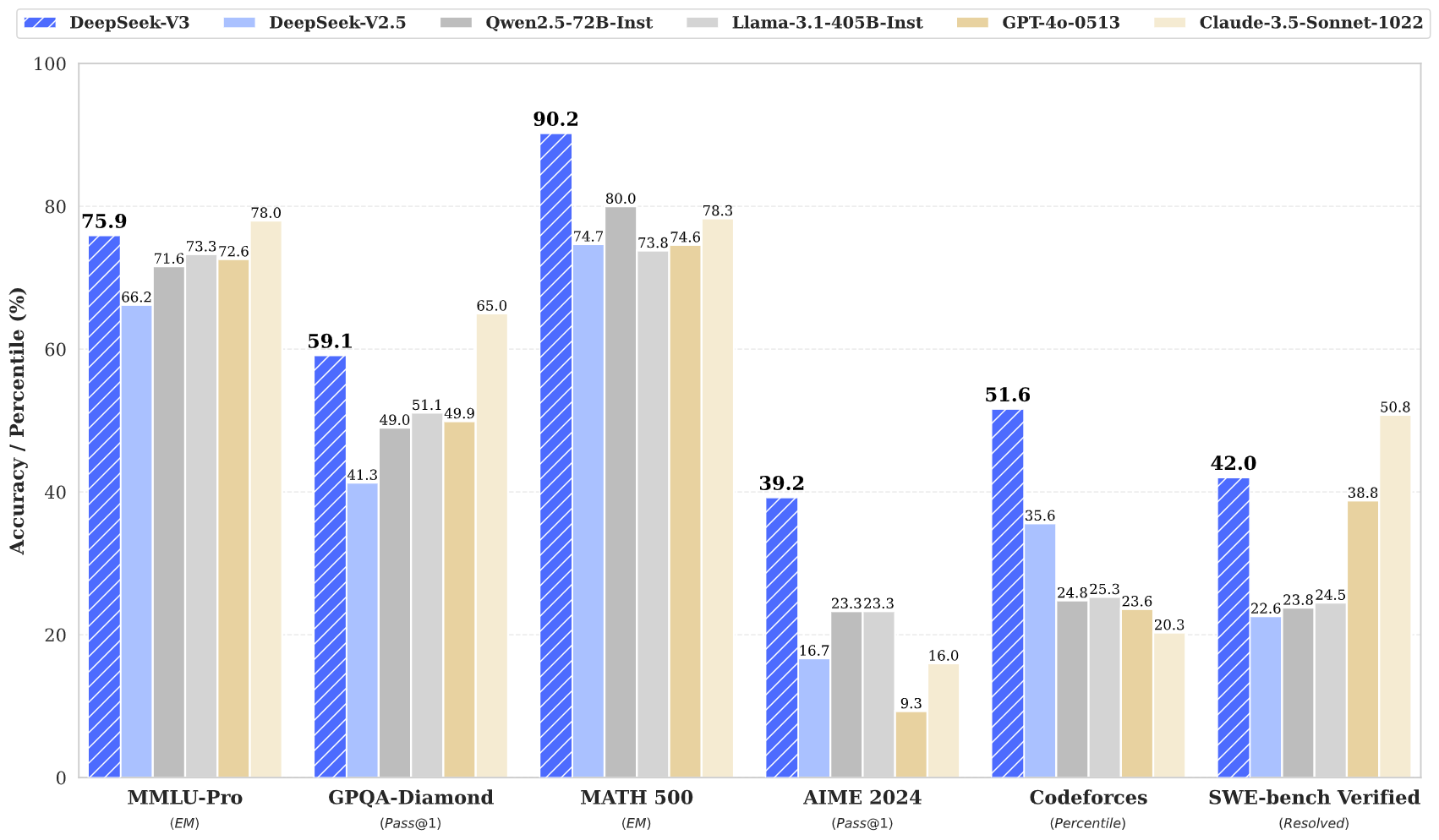

O DeepSeek v3 representa um grande avanço em modelos de linguagem de IA, com 671B parâmetros totais e 37B ativados para cada token. Construído com a inovadora arquitetura Mixture-of-Experts (MoE), o DeepSeek v3 oferece desempenho de última geração em vários benchmarks mantendo inferência eficiente.
Explore as impressionantes capacidades do DeepSeek v3 em diferentes domínios - do raciocínio complexo à geração de código
Descubra o que faz do DeepSeek v3 uma escolha líder em modelos de linguagem grandes
O DeepSeek v3 utiliza uma arquitetura inovadora Mixture-of-Experts com 671B parâmetros totais, ativando 37B parâmetros para cada token para desempenho ideal.
Pré-treinado em 14,8 trilhões de tokens de alta qualidade, o DeepSeek v3 demonstra conhecimento abrangente em vários domínios.
O DeepSeek v3 alcança resultados de última geração em múltiplos benchmarks, incluindo matemática, codificação e tarefas multilíngues.
Apesar de seu grande tamanho, o DeepSeek v3 mantém capacidades de inferência eficientes através de design inovador de arquitetura.
Com uma janela de contexto de 128K, o DeepSeek v3 pode processar e entender sequências de entrada extensas efetivamente.
O DeepSeek v3 incorpora Predição Multi-Token avançada para melhor desempenho e aceleração de inferência.
Acesse o poder do DeepSeek v3 em três passos simples
Selecione entre várias tarefas, incluindo geração de texto, conclusão de código e raciocínio matemático. O DeepSeek v3 se destaca em múltiplos domínios.
Digite seu prompt ou pergunta. A arquitetura avançada do DeepSeek v3 garante respostas de alta qualidade com seu modelo de 671B parâmetros.
Experimente o desempenho superior do DeepSeek v3 com respostas que demonstram raciocínio e compreensão avançados.
Descubra como o DeepSeek v3 está avançando o campo dos modelos de linguagem de IA
Mantenha-se atualizado com as últimas notícias e insights do DeepSeek v3

DeepSeek V3.1 — Análise completa do mais recente modelo de IA open source

DeepSeek‑V3‑0324 – Atualização com melhorias abrangentes

DeepSeek V3 – Redefinindo os padrões de eficiência em IA
O DeepSeek v3 representa o mais recente avanço em modelos de linguagem grandes, apresentando uma inovadora arquitetura Mixture-of-Experts com 671B parâmetros totais. Este modelo inovador demonstra desempenho excepcional em vários benchmarks, incluindo matemática, codificação e tarefas multilíngues.
Treinado em 14,8 trilhões de tokens diversos e incorporando técnicas avançadas como Predição Multi-Token, o DeepSeek v3 estabelece novos padrões em modelagem de linguagem de IA. O modelo suporta uma janela de contexto de 128K e oferece desempenho comparável aos principais modelos de código fechado, mantendo capacidades de inferência eficientes.
O DeepSeek v3 combina uma massiva arquitetura MoE de 671B parâmetros com recursos inovadores como Predição Multi-Token e balanceamento de carga livre de perda auxiliar, oferecendo desempenho excepcional em várias tarefas.
O DeepSeek v3 está disponível através de nossa plataforma de demonstração online e serviços de API. Você também pode baixar os pesos do modelo para implantação local.
O DeepSeek v3 demonstra desempenho superior em matemática, codificação, raciocínio e tarefas multilíngues, consistentemente alcançando resultados superiores em avaliações de benchmark.
O DeepSeek v3 suporta várias opções de implantação, incluindo GPUs NVIDIA, GPUs AMD e NPUs Huawei Ascend, com múltiplas opções de framework para desempenho ideal.
Sim, o DeepSeek v3 suporta uso comercial sujeito aos termos de licença do modelo.
O DeepSeek v3 supera outros modelos de código aberto e alcança desempenho comparável aos principais modelos de código fechado em vários benchmarks.
O DeepSeek v3 pode ser implantado usando múltiplos frameworks incluindo SGLang, LMDeploy, TensorRT-LLM, vLLM, e suporta modos de inferência FP8 e BF16.
O DeepSeek v3 possui uma janela de contexto de 128K, permitindo processar e entender sequências de entrada extensas efetivamente para tarefas complexas e conteúdo de forma longa.
O DeepSeek v3 foi pré-treinado em 14,8 trilhões de tokens diversos e de alta qualidade, seguido por estágios de Fine-Tuning Supervisionado e Aprendizado por Reforço. O processo de treinamento foi notavelmente estável sem picos de perda irrecuperáveis.
O DeepSeek v3 utiliza treinamento de precisão mista FP8 e alcança treinamento MoE eficiente entre nós através de co-design algoritmo-framework-hardware, completando o pré-treinamento com apenas 2,788M horas de GPU H800.