Funzionalità di DeepSeek v3
Esplora le straordinarie capacità di DeepSeek v3 in diversi ambiti, dal ragionamento complesso alla generazione di codice
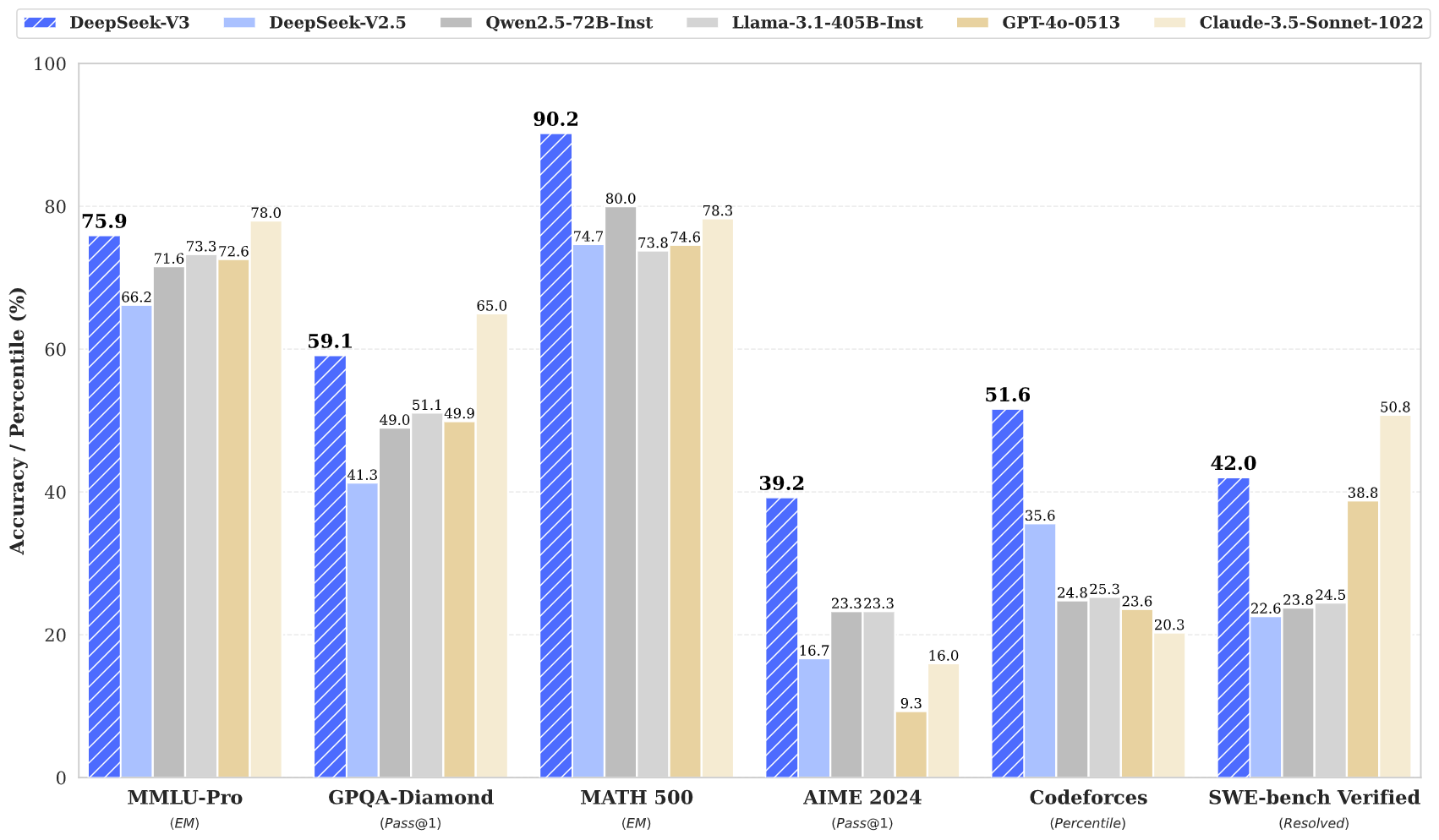

DeepSeek v3 rappresenta un importante passo avanti nei modelli linguistici dell'intelligenza artificiale, con 671 miliardi di parametri totali di cui 37 miliardi attivati per ciascun token. Basato sull'innovativa architettura Mixture-of-Experts (MoE), DeepSeek v3 offre prestazioni all'avanguardia su vari benchmark mantenendo un'inferenza efficiente.
Esplora le straordinarie capacità di DeepSeek v3 in diversi ambiti, dal ragionamento complesso alla generazione di codice
Scopri cosa rende DeepSeek v3 una scelta leader nei modelli linguistici di grandi dimensioni
DeepSeek v3 utilizza un'architettura innovativa Mixture-of-Experts con 671B parametri totali, attivando 37B parametri per ciascun token per prestazioni ottimali.
Pre-addestrato su 14,8 trilioni di token di alta qualità, DeepSeek v3 dimostra una conoscenza completa in vari domini.
DeepSeek v3 raggiunge risultati all'avanguardia su più benchmark, tra cui matematica, codifica e attività multilingue.
Nonostante le sue grandi dimensioni, DeepSeek v3 mantiene efficienti capacità di inferenza attraverso un design dell'architettura innovativo.
Con una finestra di contesto da 128K, DeepSeek v3 è in grado di elaborare e comprendere in modo efficace ampie sequenze di input.
DeepSeek v3 incorpora la previsione multi-token avanzata per prestazioni migliorate e accelerazione dell'inferenza.
Accedi alla potenza di DeepSeek v3 in tre semplici passaggi
Scegli tra varie attività tra cui la generazione di testo, il completamento del codice e il ragionamento matematico. DeepSeek v3 eccelle in più domini.
Inserisci il tuo suggerimento o domanda. L'architettura avanzata di DeepSeek v3 garantisce risposte di alta qualità con il suo modello di parametri 671B.
Sperimenta le prestazioni superiori di DeepSeek v3 con risposte che dimostrano ragionamento e comprensione avanzati.
Scopri come DeepSeek v3 sta facendo avanzare il campo dei modelli linguistici dell'intelligenza artificiale
Rimani aggiornato con le ultime notizie e approfondimenti da DeepSeek v3

DeepSeek V3.1 — Analisi completa del più recente modello IA open source

DeepSeek‑V3‑0324 – Aggiornamento completo delle capacità

DeepSeek V3 – Ridefinire gli standard di efficienza nell’IA
DeepSeek v3 rappresenta l'ultimo progresso nei modelli linguistici di grandi dimensioni, caratterizzato da un'innovativa architettura Mixture-of-Experts con parametri totali di 671B. Questo modello innovativo dimostra prestazioni eccezionali rispetto a vari benchmark, tra cui matematica, codifica e attività multilingue.
Addestrato su 14,8 trilioni di token diversi e incorporando tecniche avanzate come la previsione multi-token, DeepSeek v3 stabilisce nuovi standard nella modellazione del linguaggio AI. Il modello supporta una finestra di contesto da 128 KB e offre prestazioni paragonabili ai principali modelli closed source, pur mantenendo capacità di inferenza efficienti.
DeepSeek v3 combina un'enorme architettura MoE con parametri 671B con funzionalità innovative come la previsione multi-token e il bilanciamento del carico senza perdite ausiliarie, offrendo prestazioni eccezionali in varie attività.
DeepSeek v3 è disponibile tramite la nostra piattaforma demo online e i servizi API. Puoi anche scaricare i pesi del modello per la distribuzione locale.
DeepSeek v3 dimostra prestazioni superiori in matematica, codifica, ragionamento e attività multilingue, ottenendo costantemente i migliori risultati nelle valutazioni dei benchmark.
DeepSeek v3 supporta varie opzioni di distribuzione tra cui GPU NVIDIA, GPU AMD e NPU Huawei Ascend, con molteplici opzioni di framework per prestazioni ottimali.
Sì, DeepSeek v3 supporta l'uso commerciale soggetto ai termini di licenza del modello.
DeepSeek v3 supera gli altri modelli open source e raggiunge prestazioni paragonabili ai principali modelli closed source in vari benchmark.
DeepSeek v3 può essere distribuito utilizzando più framework tra cui SGLang, LMDeploy, TensorRT-LLM, vLLM e supporta entrambe le modalità di inferenza FP8 e BF16.
DeepSeek v3 presenta una finestra di contesto da 128K, che gli consente di elaborare e comprendere in modo efficace ampie sequenze di input per attività complesse e contenuti di lunga durata.
DeepSeek v3 è stato pre-addestrato su 14,8 trilioni di token diversi e di alta qualità, seguiti da fasi di perfezionamento supervisionato e apprendimento per rinforzo. Il processo di formazione è stato notevolmente stabile senza picchi di perdite irrecuperabili.
DeepSeek v3 utilizza l'addestramento di precisione misto FP8 e ottiene un efficiente addestramento MoE tra nodi attraverso la co-progettazione di algoritmo, framework e hardware, completando il pre-addestramento con sole 2.788 milioni di ore GPU H800.