
DeepSeek V3 – Ridefinire gli standard di efficienza nell’IA
January 13, 2025
DeepSeek V3: una svolta epocale nell’efficienza dell’IA
In uno sviluppo dirompente per la comunità dell’IA, DeepSeek V3 emerge come un modello che mette in discussione l’idea tradizionale di efficienza e convenienza nell’addestramento. Questa analisi approfondita esplora come DeepSeek V3 raggiunga prestazioni allo stato dell’arte riducendo drasticamente i requisiti di risorse.
Innovazione architetturale: la potenza del MoE
Al centro di DeepSeek V3 vi è una sofisticata architettura Mixture‑of‑Experts (MoE) che trasforma radicalmente il funzionamento dei grandi modelli linguistici. Pur contando 671 miliardi di parametri, il modello ne attiva in modo intelligente solo 37 miliardi per inferenza, segnando un cambio di paradigma nell’efficienza.
Componenti architetturali chiave:
-
Attivazione intelligente dei parametri
- Coinvolgimento selettivo degli esperti in base al compito
- Riduzione drastica dell’onere computazionale
- Prestazioni elevate con meno parametri attivi
-
Multi‑head Latent Attention (MLA)
- Migliore elaborazione del contesto
- Minore utilizzo di memoria in inferenza
- Meccanismi ottimizzati di estrazione delle informazioni
Abbattere le barriere di costo
Le implicazioni economiche delle innovazioni di DeepSeek V3 sono notevoli:
- Costo di addestramento: 5,6 milioni di $
- Durata dell’addestramento: 57 giorni
- Uso GPU: 2,788 milioni di ore GPU H800
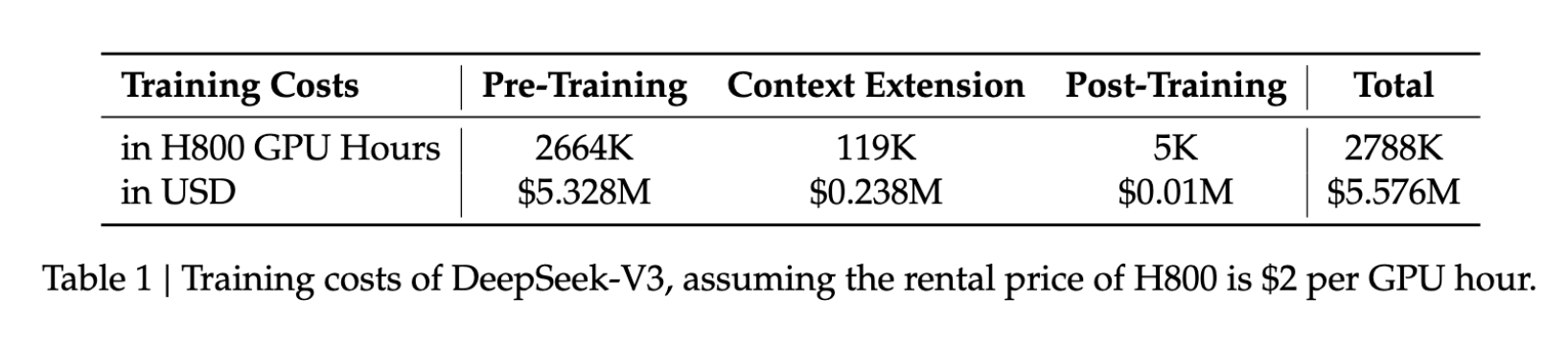
Queste cifre rappresentano una frazione delle risorse normalmente richieste per modelli comparabili, rendendo lo sviluppo di IA avanzata più accessibile a un maggior numero di organizzazioni.
Prestazioni che parlano da sé
Nonostante il design orientato all’efficienza, DeepSeek V3 offre prestazioni eccellenti su benchmark chiave:
| Benchmark | Punteggio |
|---|---|
| MMLU | 87,1% |
| BBH | 87,5% |
| DROP | 89,0% |
| HumanEval | 65,2% |
| MBPP | 75,4% |
| GSM8K | 89,3% |
Questi risultati posizionano DeepSeek V3 al livello dei leader del settore come GPT‑4 e Claude 3.5 Sonnet, in particolare per ragionamento complesso e programmazione.
Innovazioni tecniche
1. Bilanciamento del carico senza perdita ausiliaria
Il modello introduce un approccio inedito al bilanciamento che mantiene prestazioni ottimali senza gli svantaggi dei meccanismi di auxiliary loss.
2. Predizione multi‑token
Grazie a capacità avanzate di predizione multi‑token, DeepSeek V3 raggiunge:
- Maggiore velocità di generazione
- Migliore comprensione contestuale
- Maggiore efficienza nell’elaborazione dei token
Applicazioni pratiche
Le implicazioni pratiche sono ampie:
- Finestra di contesto estesa: 128.000 token per analisi documentali approfondite
- Velocità di generazione: fino a 90 token/secondo
- Efficienza delle risorse: costi di deploy significativamente ridotti
Il futuro dello sviluppo in IA
DeepSeek V3 non è solo un nuovo rilascio: segna un cambiamento profondo nel modo di approcciare lo sviluppo. Dimostrando che è possibile ottenere prestazioni top con molte meno risorse, apre la strada a:
- L’ingresso di organizzazioni più piccole
- Pratiche di sviluppo più sostenibili
- Innovazione accelerata nell’architettura dei modelli
Conclusione
DeepSeek V3 è una prova concreta della forza del pensiero innovativo nello sviluppo dell’IA. Mettendo in discussione approcci convenzionali di architettura e training, stabilisce nuovi standard di efficienza mantenendo prestazioni d’eccellenza.
«DeepSeek V3 non si limita a spingere i confini del possibile nell’IA: li ridefinisce. Il suo approccio rivoluzionario a efficienza e prestazioni fissa un nuovo standard per l’intero settore.»