DeepSeek v3 功能
探索 DeepSeek v3 跨不同領域的令人印象深刻的功能 - 從複雜推理到程式碼生成

DeepSeek v3 代表了 AI 語言模型的重大突破,共有 671B 個參數,每個 token 啟動 37B 個參數。 DeepSeek v3 基於創新的專家混合 (MoE) 架構而構建,在各種基準測試中提供最先進的性能,同時保持高效的推理。
探索 DeepSeek v3 跨不同領域的令人印象深刻的功能 - 從複雜推理到程式碼生成
了解 DeepSeek v3 為何成為大型語言模式的領先選擇
DeepSeek v3 採用創新的專家混合架構,總參數為 671B,為每個令牌啟動 37B 參數以獲得最佳效能。
DeepSeek v3 經過 14.8 兆個高品質代幣的預訓練,展現了跨各個領域的全面知識。
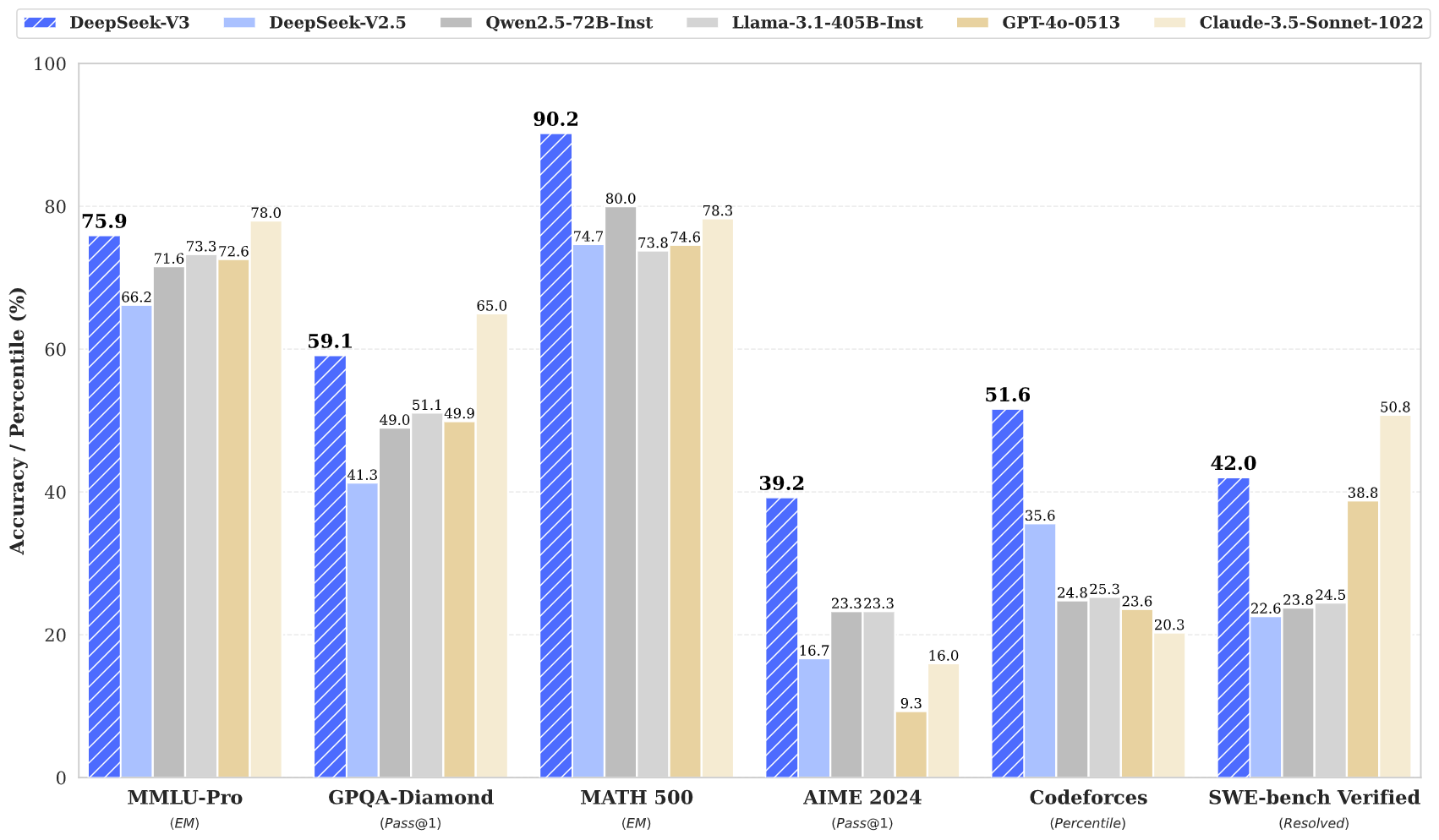
DeepSeek v3 在多個基準測試中取得了最先進的結果,包括數學、編碼和多語言任務。
儘管體積較大,DeepSeek v3 透過創新的架構設計保持了高效的推理能力。
憑藉 128K 上下文窗口,DeepSeek v3 可以有效地處理和理解大量輸入序列。
DeepSeek v3 結合了先進的多令牌預測,以增強效能和推理加速。
只需三個簡單步驟即可發揮 DeepSeek v3 的強大功能
從各種任務中進行選擇,包括文字生成、程式碼完成和數學推理。 DeepSeek v3 在多個領域表現出色。
輸入您的提示或問題。 DeepSeek v3 的先進架構透過其 671B 參數模型確保高品質回應。
體驗 DeepSeek v3 的卓越性能以及展示高級推理和理解的回應。
了解 DeepSeek v3 如何推進 AI 語言模型領域
DeepSeek v3 代表了大型語言模型的最新進展,具有突破性的 Mixture-of-Experts 架構,總參數達 671B。 這種創新模型在各種基準測試中表現出了卓越的性能,包括數學、編碼和多語言任務。
DeepSeek v3 經過 14.8 兆個不同代幣的訓練,並結合了多代幣預測等先進技術,為 AI 語言建模樹立了新標準。 該模型支援 128K 上下文窗口,提供與領先的閉源模型相當的性能,同時保持高效的推理能力。
DeepSeek v3 將大規模 671B 參數 MoE 架構與多令牌預測和輔助無遺失負載平衡等創新功能相結合,在各種任務中提供卓越的效能。
DeepSeek v3 可透過我們的線上簡報平台和 API 服務取得。 您也可以下載模型權重以進行本機部署。
DeepSeek v3 在數學、編碼、推理和多語言任務方面表現出卓越的性能,在基準評估中始終取得最高成績。
DeepSeek v3支援多種部署選項,包括NVIDIA GPU、AMD GPU和華為Ascend NPU,並具有多種框架選項以實現最佳效能。
是的,DeepSeek v3 支援商業用途,但須遵守模型授權條款。
DeepSeek v3 的性能優於其他開源模型,並在各種基準測試中實現與領先的閉源模型相當的性能。
DeepSeek v3可以使用SGLang、LMDeploy、TensorRT-LLM、vLLM等多種框架進行部署,並支援FP8和BF16推理模式。
DeepSeek v3 具有 128K 上下文窗口,使其能夠有效處理和理解複雜任務和長格式內容的大量輸入序列。
DeepSeek v3 在 14.8 兆個多樣化的高品質代幣上進行了預訓練,隨後是監督微調和強化學習階段。 訓練過程非常穩定,沒有出現不可挽回的損失高峰。
DeepSeek v3採用FP8混合精準度訓練,透過演算法-框架-硬體協同設計實現高效率的跨節點MoE訓練,僅以2.788M H800 GPU小時完成預訓練。


