قدرات DeepSeek v3
اكتشف الإمكانات الرائعة لبرنامج DeepSeek v3 عبر مجالات مختلفة - بدءًا من التفكير المعقد وحتى إنشاء التعليمات البرمجية

يمثل DeepSeek v3 طفرة كبيرة في نماذج لغة الذكاء الاصطناعي، حيث يضم إجمالي 671B من المعلمات مع 37B مفعلة لكل رمز مميز. تم تصميم DeepSeek v3 استنادًا إلى بنية Mixture of Experts (MoE) المبتكرة، وهو يوفر أداءً متطورًا عبر معايير مختلفة مع الحفاظ على الاستدلال الفعال.
اكتشف الإمكانات الرائعة لبرنامج DeepSeek v3 عبر مجالات مختلفة - بدءًا من التفكير المعقد وحتى إنشاء التعليمات البرمجية
اكتشف ما يجعل DeepSeek v3 خيارًا رائدًا في نماذج اللغات الكبيرة
يستخدم DeepSeek v3 بنية مبتكرة من مزيج من الخبراء مع إجمالي 671B من المعلمات، وتنشيط 37B من المعلمات لكل رمز للحصول على الأداء الأمثل.
بعد تدريبه مسبقًا على 14.8 تريليون رمز مميز عالي الجودة، يُظهر DeepSeek v3 معرفة شاملة عبر مختلف المجالات.
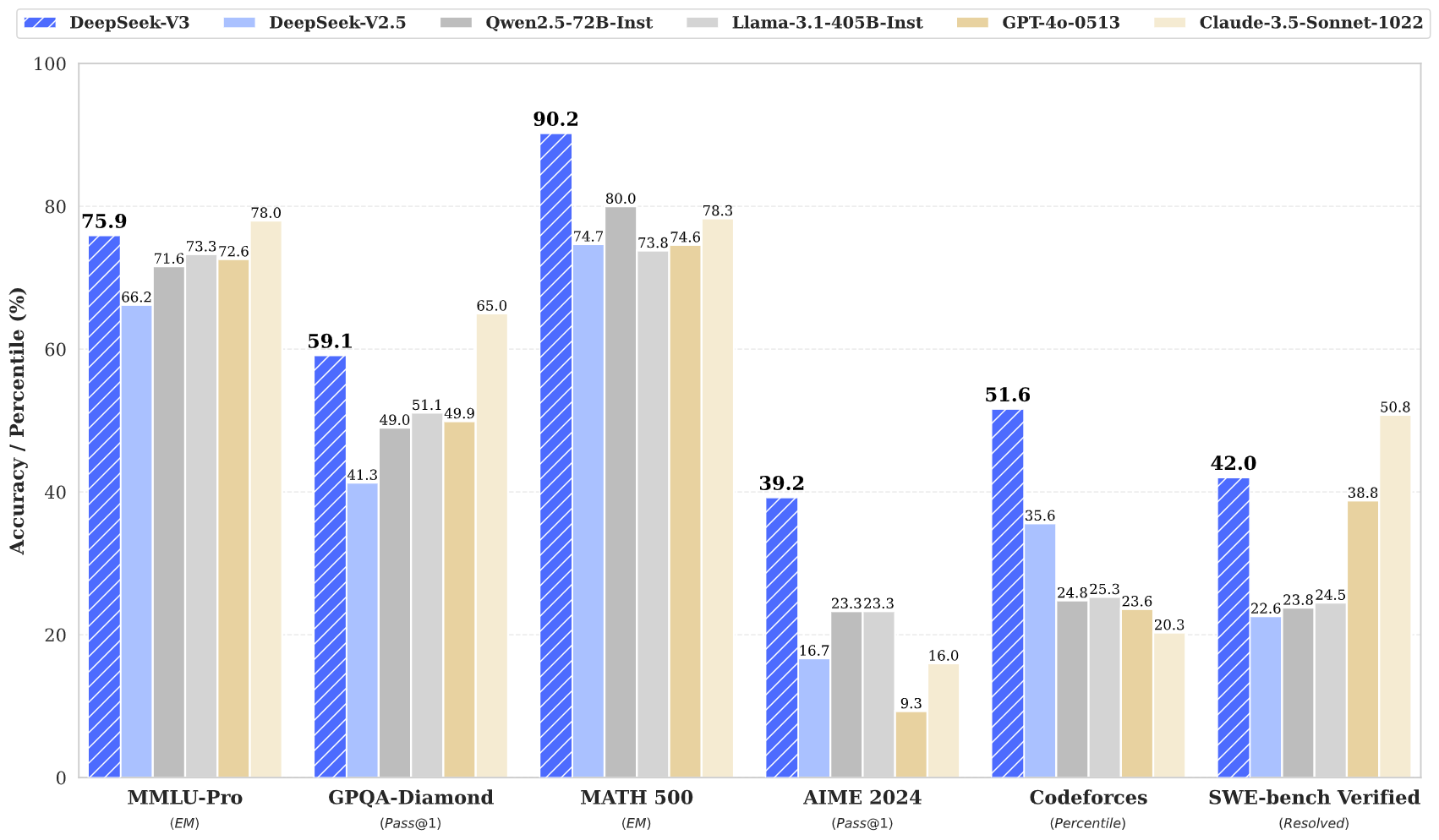
يحقق DeepSeek v3 أحدث النتائج عبر معايير متعددة، بما في ذلك الرياضيات والبرمجة والمهام متعددة اللغات.
على الرغم من حجمه الكبير، يحتفظ DeepSeek v3 بقدرات استدلالية فعالة من خلال التصميم المعماري المبتكر.
من خلال نافذة سياق بحجم 128 كيلو بايت، يستطيع DeepSeek v3 معالجة وفهم تسلسلات الإدخال الشاملة بشكل فعال.
يتضمن DeepSeek v3 تنبؤًا متقدمًا للرموز المتعددة لتحسين الأداء وتسريع الاستدلال.
يمكنك الوصول إلى قوة DeepSeek v3 في ثلاث خطوات بسيطة
اختر من بين المهام المختلفة بما في ذلك إنشاء النص وإكمال التعليمات البرمجية والتفكير الرياضي. يتفوق DeepSeek v3 عبر مجالات متعددة.
أدخل موجهك أو سؤالك. تضمن البنية المتقدمة لـ DeepSeek v3 استجابات عالية الجودة من خلال نموذج المعلمة 671B الخاص به.
استمتع بأداء DeepSeek v3 المتفوق من خلال الاستجابات التي تُظهر التفكير والفهم المتقدمين.
اكتشف كيف يعمل DeepSeek v3 على تطوير مجال نماذج لغة الذكاء الاصطناعي
ابق على اطلاع بأحدث الأخبار والأفكار من DeepSeek v3

DeepSeek V3.1 — تحليل شامل لأحدث نموذج ذكاء اصطناعي مفتوح المصدر

تحديث DeepSeek‑V3‑0324 — ترقيات شاملة في القدرات

DeepSeek V3 — إعادة تعريف معايير كفاءة الذكاء الاصطناعي
يمثل DeepSeek v3 أحدث التطورات في نماذج اللغات الكبيرة، ويتميز ببنية Mixture-of-Experts الرائدة مع إجمالي 671B من المعلمات. يُظهر هذا النموذج المبتكر أداءً استثنائيًا عبر معايير مختلفة، بما في ذلك الرياضيات والبرمجة والمهام متعددة اللغات.
تم تدريب DeepSeek v3 على 14.8 تريليون رمز متنوع ودمج تقنيات متقدمة مثل Multi-Token Prediction، ويضع معايير جديدة في نمذجة لغة الذكاء الاصطناعي. يدعم النموذج نافذة سياق بحجم 128 كيلو بايت ويقدم أداءً مشابهًا للنماذج الرائدة مغلقة المصدر مع الحفاظ على قدرات الاستدلال الفعالة.
يجمع DeepSeek v3 بين بنية MoE ذات معلمة 671B الضخمة وميزات مبتكرة مثل التنبؤ بالرموز المتعددة وموازنة التحميل الإضافية بدون خسارة، مما يوفر أداءً استثنائيًا عبر المهام المختلفة.
يتوفر DeepSeek v3 من خلال منصتنا التجريبية عبر الإنترنت وخدمات API. يمكنك أيضًا تنزيل أوزان النموذج للنشر المحلي.
يُظهر DeepSeek v3 أداءً فائقًا في الرياضيات والبرمجة والاستدلال والمهام متعددة اللغات، ويحقق باستمرار أفضل النتائج في التقييمات المعيارية.
يدعم DeepSeek v3 خيارات النشر المتنوعة بما في ذلك وحدات معالجة الرسومات NVIDIA ووحدات معالجة الرسومات AMD ووحدات Huawei Ascend NPUs، مع خيارات إطار عمل متعددة لتحقيق الأداء الأمثل.
نعم، يدعم DeepSeek v3 الاستخدام التجاري الخاضع لشروط الترخيص النموذجية.
يتفوق DeepSeek v3 على النماذج الأخرى مفتوحة المصدر ويحقق أداءً مشابهًا للنماذج الرائدة مغلقة المصدر عبر معايير مختلفة.
يمكن نشر DeepSeek v3 باستخدام أطر عمل متعددة بما في ذلك SGLang وLMDeploy وTensorRT-LLM وvLLM، ويدعم وضعي الاستدلال FP8 وBF16.
يتميز DeepSeek v3 بنافذة سياق بحجم 128 كيلو بايت، مما يسمح له بمعالجة وفهم تسلسلات الإدخال الشاملة بشكل فعال للمهام المعقدة والمحتوى الطويل.
تم تدريب DeepSeek v3 مسبقًا على 14.8 تريليون رمز مميز متنوع وعالي الجودة، تليها مراحل التعلم المعزز والضبط الدقيق الخاضعة للإشراف. كانت عملية التدريب مستقرة بشكل ملحوظ مع عدم وجود زيادات في الخسائر غير قابلة للاسترداد.
يستخدم DeepSeek v3 التدريب الدقيق المختلط FP8 ويحقق تدريبًا فعالاً على MoE عبر العقد من خلال التصميم المشترك للأجهزة وإطار عمل الخوارزمية، مما يكمل التدريب المسبق بـ 2.788 مليون ساعة وحدة معالجة رسوميات H800 فقط.