DeepSeek v3 功能
探索 DeepSeek v3 跨不同领域的令人印象深刻的功能 - 从复杂推理到代码生成

DeepSeek v3 代表了 AI 语言模型的重大突破,共有 671B 个参数,每个 token 激活 37B 个参数。 DeepSeek v3 基于创新的专家混合 (MoE) 架构而构建,在各种基准测试中提供最先进的性能,同时保持高效的推理。
探索 DeepSeek v3 跨不同领域的令人印象深刻的功能 - 从复杂推理到代码生成
了解 DeepSeek v3 为何成为大型语言模型的领先选择
DeepSeek v3 采用创新的专家混合架构,总参数为 671B,为每个令牌激活 37B 参数以获得最佳性能。
DeepSeek v3 经过 14.8 万亿个高质量代币的预训练,展示了跨各个领域的全面知识。
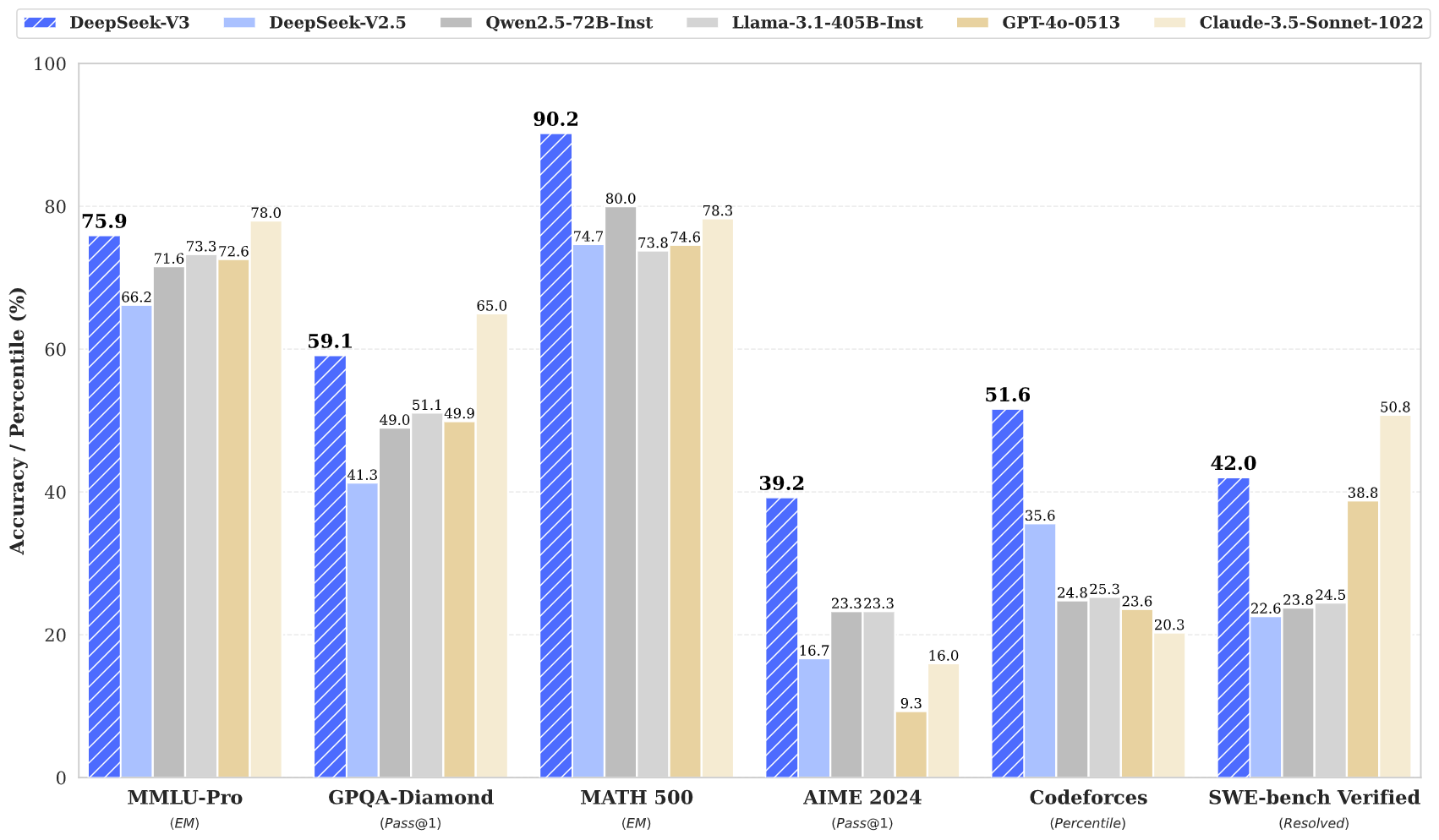
DeepSeek v3 在多个基准测试中取得了最先进的结果,包括数学、编码和多语言任务。
尽管体积较大,DeepSeek v3 通过创新的架构设计保持了高效的推理能力。
凭借 128K 上下文窗口,DeepSeek v3 可以有效地处理和理解大量输入序列。
DeepSeek v3 结合了先进的多令牌预测,以增强性能和推理加速。
只需三个简单步骤即可发挥 DeepSeek v3 的强大功能
从各种任务中进行选择,包括文本生成、代码完成和数学推理。 DeepSeek v3 在多个领域表现出色。
输入您的提示或问题。 DeepSeek v3 的先进架构通过其 671B 参数模型确保高质量响应。
体验 DeepSeek v3 的卓越性能以及展示高级推理和理解的响应。
了解 DeepSeek v3 如何推进 AI 语言模型领域
DeepSeek v3 代表了大型语言模型的最新进展,具有突破性的 Mixture-of-Experts 架构,总参数达 671B。 这种创新模型在各种基准测试中表现出了卓越的性能,包括数学、编码和多语言任务。
DeepSeek v3 经过 14.8 万亿个不同代币的训练,并结合了多代币预测等先进技术,为 AI 语言建模树立了新标准。 该模型支持 128K 上下文窗口,提供与领先的闭源模型相当的性能,同时保持高效的推理能力。
DeepSeek v3 将大规模 671B 参数 MoE 架构与多令牌预测和辅助无丢失负载平衡等创新功能相结合,在各种任务中提供卓越的性能。
DeepSeek v3 可通过我们的在线演示平台和 API 服务获取。 您还可以下载模型权重以进行本地部署。
DeepSeek v3 在数学、编码、推理和多语言任务方面表现出卓越的性能,在基准评估中始终取得最高成绩。
DeepSeek v3支持多种部署选项,包括NVIDIA GPU、AMD GPU和华为Ascend NPU,并具有多种框架选项以实现最佳性能。
是的,DeepSeek v3 支持商业用途,但须遵守模型许可条款。
DeepSeek v3 的性能优于其他开源模型,并在各种基准测试中实现与领先的闭源模型相当的性能。
DeepSeek v3可以使用SGLang、LMDeploy、TensorRT-LLM、vLLM等多种框架进行部署,并支持FP8和BF16推理模式。
DeepSeek v3 具有 128K 上下文窗口,使其能够有效处理和理解复杂任务和长格式内容的大量输入序列。
DeepSeek v3 在 14.8 万亿个多样化的高质量代币上进行了预训练,随后是监督微调和强化学习阶段。 训练过程非常稳定,没有出现不可挽回的损失峰值。
DeepSeek v3采用FP8混合精度训练,通过算法-框架-硬件协同设计实现高效的跨节点MoE训练,仅用2.788M H800 GPU小时完成预训练。


