
DeepSeek V3 —— 重新定义 AI 效率标准
January 13, 2025
DeepSeek V3:AI 效率的颠覆性突破
在 AI 社区的一项里程碑式进展中,DeepSeek V3 以革命性姿态出现,挑战我们对模型训练效率与成本效益的传统认知。本文将系统解析 DeepSeek V3 如何在显著降低资源需求的同时,依旧实现业界前沿的性能表现。
架构创新:MoE 的力量
DeepSeek V3 的核心采用精妙的 Mixture‑of‑Experts(MoE) 架构,从根本上改变了大型语言模型的运行方式。尽管模型拥有 6710 亿参数,但每次推理仅智能激活 370 亿参数,在效率上实现范式转变。
关键架构组件:
-
参数的智能激活
- 根据任务需求选择性启用专家
- 显著降低计算开销
- 在更少激活参数的前提下保持高质量输出
-
Multi‑head Latent Attention(MLA)
- 增强上下文处理能力
- 推理阶段占用更少内存
- 信息抽取机制更加高效
打破成本壁垒
DeepSeek V3 的创新带来可观的成本收益:
- 训练成本:$5.6M
- 训练时长:57 天
- GPU 使用量:278.8 万小时(H800)
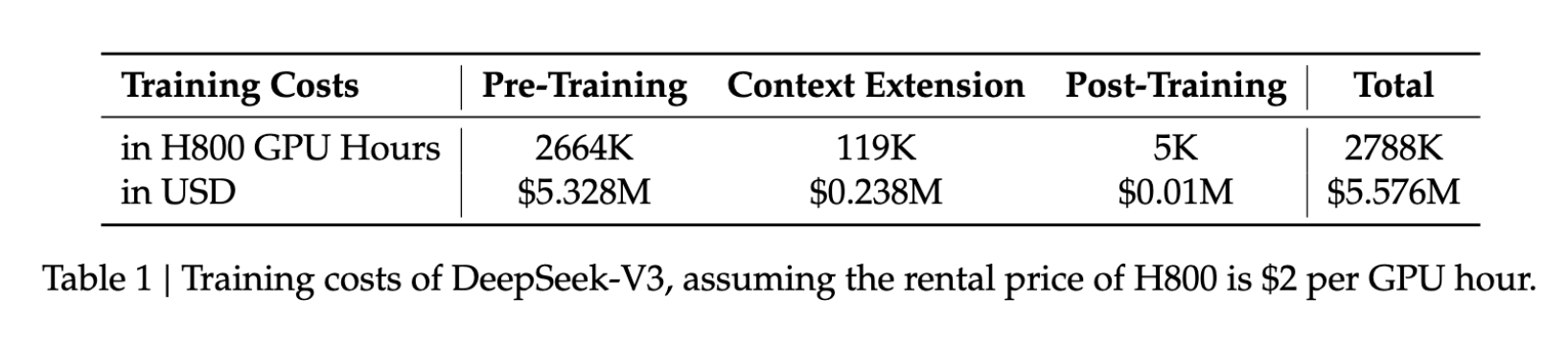
与同量级模型相比,这些数字仅为其所需资源的一小部分,使得高级 AI 开发对更多组织变得触手可及。
过硬的性能表现
在追求效率的同时,DeepSeek V3 依然在关键基准中展现卓越成绩:
| Benchmark | 分数 |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
这些结果表明,DeepSeek V3 与 GPT‑4、Claude 3.5 Sonnet 等行业领军模型比肩,尤其在复杂推理与编码任务上竞争力突出。
技术创新
1. 无辅助损失的负载均衡
引入全新负载均衡策略,在避免传统 auxiliary loss 副作用的同时维持最优性能。
2. 多 Token 预测
借助先进的多 Token 预测能力,DeepSeek V3 实现:
- 更快的文本生成速度
- 更强的上下文理解
- 更高效的 Token 处理
实际应用价值
DeepSeek V3 的能力在实践中具备广泛影响:
- 超长上下文:128,000 tokens,支持全面的文档分析
- 生成速度:最高 90 tokens/s
- 资源效率:显著降低部署成本
AI 开发的未来
DeepSeek V3 不只是一次版本更新;它标志着 AI 开发范式的转变。其证明了在大幅减少资源投入的前提下,依旧可以达到顶级性能,由此为以下方向打开新可能:
- 更多中小组织进入 AI 领域
- 更加可持续的 AI 开发实践
- 模型架构创新的加速
结语
DeepSeek V3 诠释了创新思维在 AI 开发中的力量。通过打破传统的架构与训练路径,它在确保精英级表现的同时,树立了效率新标杆。
“DeepSeek V3 不只是推动 AI 可能性的边界——它在重新定义这些边界。其在效率与性能上的革命性方法,为整个行业设定了新标准。”