DeepSeek v3 の機能
複雑な推論からコード生成まで、さまざまなドメインにわたる DeepSeek v3 の優れた機能を探索します。

DeepSeek v3 は AI 言語モデルにおける大きな進歩を表しており、合計 671B のパラメーターと各トークンごとに有効化される 37B のパラメーターを特徴としています。 革新的な Mixture-of-Experts (MoE) アーキテクチャに基づいて構築された DeepSeek v3 は、効率的な推論を維持しながら、さまざまなベンチマークにわたって最先端のパフォーマンスを提供します。
複雑な推論からコード生成まで、さまざまなドメインにわたる DeepSeek v3 の優れた機能を探索します。
DeepSeek v3 が大規模言語モデルにおける主要な選択肢となっている理由を確認してください
DeepSeek v3 は、合計 671B のパラメーターを備えた革新的な専門家混合アーキテクチャを利用し、最適なパフォーマンスを得るためにトークンごとに 37B のパラメーターをアクティブにします。
14.8 兆の高品質トークンで事前トレーニングされた DeepSeek v3 は、さまざまなドメインにわたる包括的な知識を実証します。
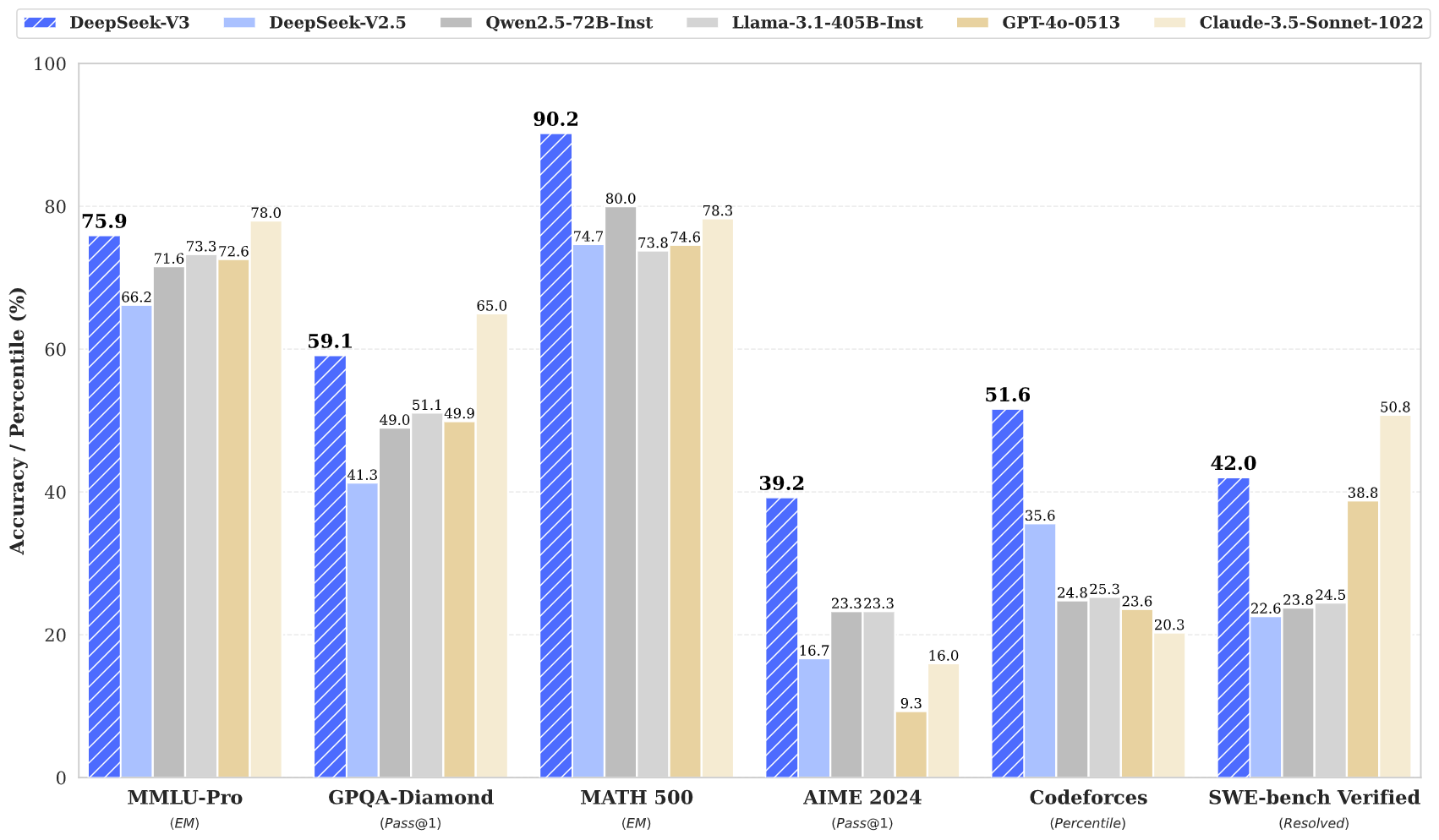
DeepSeek v3 は、数学、コーディング、多言語タスクを含む複数のベンチマークにわたって最先端の結果を達成します。
DeepSeek v3 は、そのサイズが大きいにもかかわらず、革新的なアーキテクチャ設計を通じて効率的な推論機能を維持しています。
DeepSeek v3 は 128K のコンテキスト ウィンドウを備えており、広範な入力シーケンスを効果的に処理して理解できます。
DeepSeek v3 には、高度なマルチトークン予測が組み込まれており、パフォーマンスと推論の高速化が強化されています。
3 つの簡単なステップで DeepSeek v3 の機能にアクセスします
テキスト生成、コード補完、数学的推論などのさまざまなタスクから選択します。 DeepSeek v3 は、複数のドメインにわたって優れた性能を発揮します。
プロンプトまたは質問を入力します。 DeepSeek v3 の高度なアーキテクチャにより、671B パラメータ モデルによる高品質の応答が保証されます。
高度な推論と理解を示す応答により、DeepSeek v3 の優れたパフォーマンスを体験してください。
DeepSeek v3 が AI 言語モデルの分野をどのように進歩させているかをご覧ください
DeepSeek v3 からの最新ニュースと洞察を常に入手してください
DeepSeek v3 は、大規模言語モデルの最新の進歩を表しており、合計 671B のパラメータを備えた画期的な専門家混合アーキテクチャを特徴としています。 この革新的なモデルは、数学、コーディング、多言語タスクなどのさまざまなベンチマークにわたって優れたパフォーマンスを示します。
14.8 兆の多様なトークンでトレーニングされ、マルチトークン予測などの高度な技術を組み込んだ DeepSeek v3 は、AI 言語モデリングの新しい標準を確立します。 このモデルは 128K コンテキスト ウィンドウをサポートし、効率的な推論機能を維持しながら、主要なクローズドソース モデルと同等のパフォーマンスを提供します。
DeepSeek v3 は、大規模な 671B パラメータ MoE アーキテクチャと、マルチトークン予測や補助損失のない負荷分散などの革新的な機能を組み合わせ、さまざまなタスクにわたって優れたパフォーマンスを提供します。
DeepSeek v3 は、オンライン デモ プラットフォームおよび API サービスを通じて入手できます。 ローカル展開用のモデルの重みをダウンロードすることもできます。
DeepSeek v3 は、数学、コーディング、推論、多言語タスクで優れたパフォーマンスを示し、ベンチマーク評価で常に最高の結果を達成しています。
DeepSeek v3 は、NVIDIA GPU、AMD GPU、Huawei Ascend NPU などのさまざまな展開オプションをサポートし、最適なパフォーマンスを実現する複数のフレームワーク オプションを備えています。
はい、DeepSeek v3 はモデル ライセンス条項に従って商用利用をサポートしています。
DeepSeek v3 は他のオープンソース モデルを上回り、さまざまなベンチマークにわたって主要なクローズドソース モデルと同等のパフォーマンスを達成します。
DeepSeek v3 は、SGLang、LMDeploy、TensorRT-LLM、vLLM などの複数のフレームワークを使用してデプロイでき、FP8 と BF16 の両方の推論モードをサポートします。
DeepSeek v3 は 128K コンテキスト ウィンドウを備えており、複雑なタスクや長い形式のコンテンツに対して広範な入力シーケンスを効果的に処理して理解することができます。
DeepSeek v3 は、14.8 兆の多様で高品質なトークンで事前トレーニングされ、その後、教師あり微調整および強化学習ステージが続きます。 トレーニングプロセスは非常に安定しており、回復不能な損失の急増はありませんでした。
DeepSeek v3 は、FP8 混合精度トレーニングを利用し、アルゴリズム、フレームワーク、ハードウェアの共同設計を通じて効率的なクロスノード MoE トレーニングを実現し、わずか 278 万 8000 万 H800 GPU 時間で事前トレーニングを完了します。


