
DeepSeek V3 — AI効率の新基準を再定義する
January 13, 2025
DeepSeek V3:AI効率における画期的ブレイクスルー
AIコミュニティにおける画期的進展として、DeepSeek V3 は学習の効率性とコストの常識を覆すモデルとして登場しました。本稿では、DeepSeek V3 が必要リソースを大幅に削減しながら、いかに最先端の性能を実現しているかを詳しく解説します。
アーキテクチャの革新:MoE の力
DeepSeek V3 の中核には、洗練された Mixture‑of‑Experts(MoE) アーキテクチャがあります。総 6,710 億パラメータ を有しつつ、推論時には 370 億 のみを賢く活性化することで、効率性におけるパラダイムシフトを実現しています。
主要コンポーネント:
-
パラメータのインテリジェント活性化
- タスク要件に基づく選択的なエキスパート起用
- 計算負荷の大幅低減
- 活性化パラメータが少なくても高品質を維持
-
Multi‑head Latent Attention(MLA)
- 文脈処理能力の強化
- 推論時のメモリ消費を削減
- 情報抽出メカニズムの最適化
コストの壁を打破
DeepSeek V3 のイノベーションは、コスト面で顕著な成果をもたらします:
- 学習コスト:$5.6M
- 学習期間:57 日
- GPU 使用量:H800 で 278.8 万時間
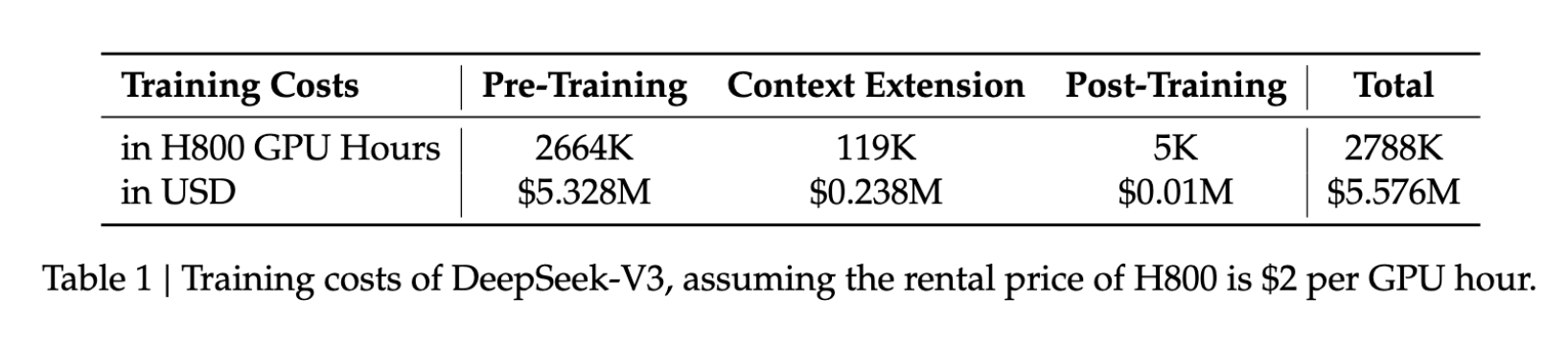
同規模モデルに比べ、これらの数値は必要リソースのごく一部に過ぎず、高度なAI開発をより多くの組織へ開かれたものにします。
語るに足るパフォーマンス
効率重視の設計でありながら、DeepSeek V3 は主要ベンチマークで優れた成績を示します:
| ベンチマーク | スコア |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
これらの結果は、特に複雑な推論やコーディング課題において、DeepSeek V3 が GPT‑4 や Claude 3.5 Sonnet といった業界トップと肩を並べることを示しています。
技術的イノベーション
1. 補助損失を用いない負荷分散
補助損失メカニズムの欠点を回避しつつ、最適性能を維持する新たな負荷分散手法を導入。
2. マルチトークン予測
高度なマルチトークン予測能力により、DeepSeek V3 は次を実現:
- 生成速度の向上
- 文脈理解の強化
- トークン処理の高効率化
実用的な応用
DeepSeek V3 の能力は実務面で広範な影響を持ちます:
- 拡張コンテキストウィンドウ:128,000 トークンで包括的な文書分析を実施 |- 生成速度:最大 90 トークン/秒
- リソース効率:展開コストを大幅削減
AI 開発の未来
DeepSeek V3 は単なるバージョンアップではなく、AI 開発のパラダイム転換を象徴します。大幅に少ないリソースでトップクラスの性能を実現できることを示し、次の可能性を切り開きます:
- 中小規模組織の参入拡大
- より持続可能な開発プラクティス
- モデルアーキテクチャの迅速な革新
まとめ
DeepSeek V3 は、AI 開発における創造的思考の力を体現しています。従来のアーキテクチャや学習手法を見直すことで、エリート級の性能を保ちながら、効率の新たな標準を打ち立てています。
「DeepSeek V3 は、AI の可能性の境界を押し広げるだけでなく、それ自体を再定義します。効率と性能における革命的アプローチは、業界全体の新たな基準を打ち立てます。」