Capacités de DeepSeek v3
Explorez les capacités impressionnantes de DeepSeek v3 dans différents domaines - du raisonnement complexe à la génération de code
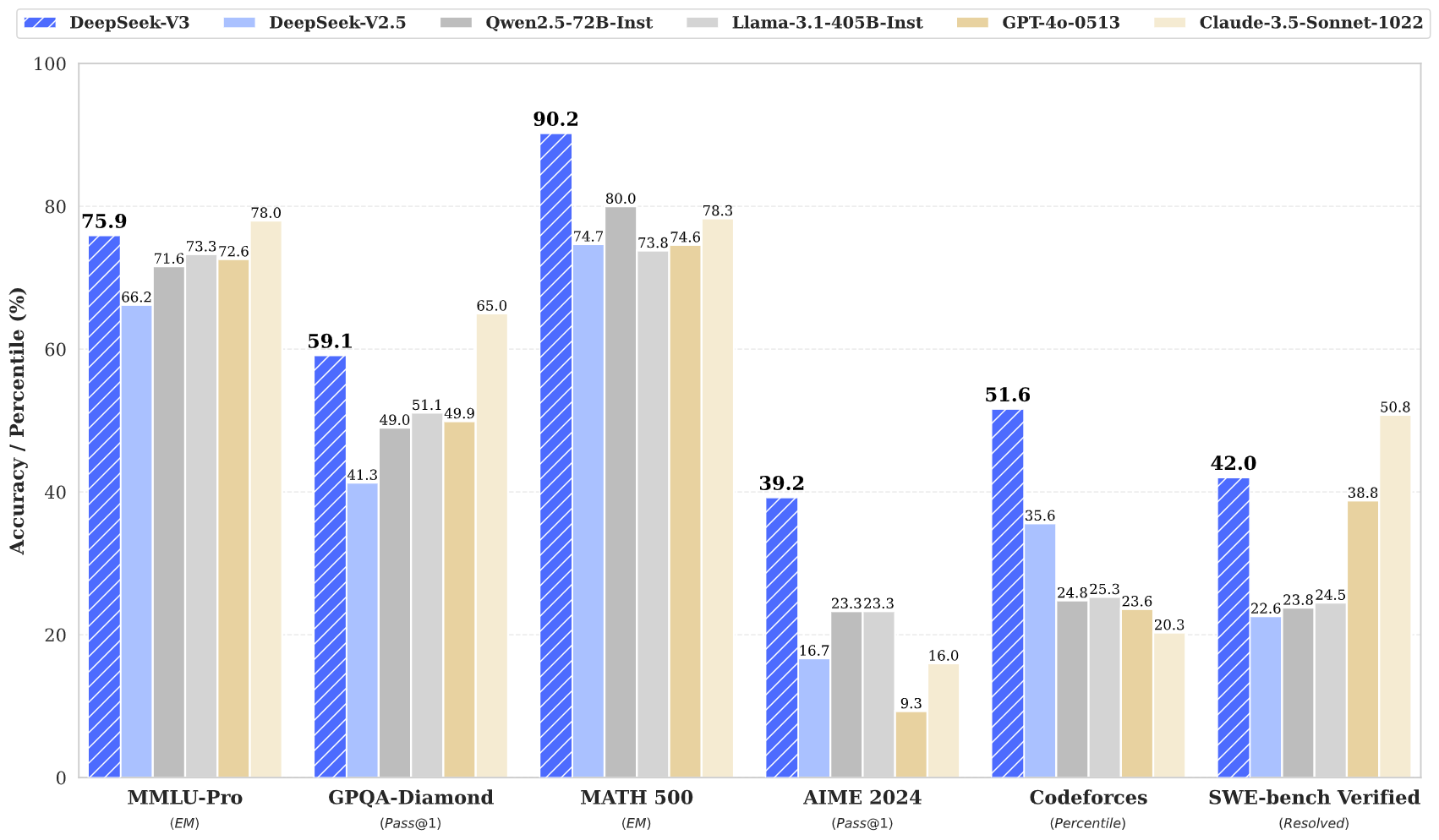

DeepSeek v3 représente une avancée majeure dans les modèles de langage IA, avec 671B paramètres au total dont 37B activés pour chaque token. Construit sur une architecture innovante Mixture-of-Experts (MoE), DeepSeek v3 offre des performances de pointe sur divers benchmarks tout en maintenant une inférence efficace.
Explorez les capacités impressionnantes de DeepSeek v3 dans différents domaines - du raisonnement complexe à la génération de code
Découvrez ce qui fait de DeepSeek v3 un choix de premier plan parmi les grands modèles de langage
DeepSeek v3 utilise une architecture innovante Mixture-of-Experts avec 671B paramètres au total, activant 37B paramètres pour chaque token pour des performances optimales.
Pré-entraîné sur 14,8 billions de tokens de haute qualité, DeepSeek v3 démontre une connaissance approfondie dans divers domaines.
DeepSeek v3 atteint des résultats état de l'art sur plusieurs benchmarks, notamment en mathématiques, codage et tâches multilingues.
Malgré sa grande taille, DeepSeek v3 maintient des capacités d'inférence efficaces grâce à une conception architecturale innovante.
Avec une fenêtre de contexte de 128K, DeepSeek v3 peut traiter et comprendre efficacement des séquences d'entrée étendues.
DeepSeek v3 intègre une prédiction multi-tokens avancée pour des performances améliorées et une accélération de l'inférence.
Accédez à la puissance de DeepSeek v3 en trois étapes simples
Sélectionnez parmi diverses tâches incluant la génération de texte, la complétion de code et le raisonnement mathématique. DeepSeek v3 excelle dans de multiples domaines.
Entrez votre prompt ou question. L'architecture avancée de DeepSeek v3 assure des réponses de haute qualité avec son modèle de 671B paramètres.
Découvrez les performances supérieures de DeepSeek v3 avec des réponses démontrant un raisonnement et une compréhension avancés.
Découvrez comment DeepSeek v3 fait progresser le domaine des modèles de langage IA
Restez informé des dernières nouvelles et perspectives de DeepSeek v3

DeepSeek V3.1 — Analyse complète du dernier modèle IA open source

DeepSeek‑V3‑0324 – Améliorations globales de l’ensemble des capacités

DeepSeek V3 - Redéfinir les standards d’efficacité en IA
DeepSeek v3 représente la dernière avancée en matière de grands modèles de langage, avec une architecture révolutionnaire Mixture-of-Experts totalisant 671B paramètres. Ce modèle innovant démontre des performances exceptionnelles dans divers benchmarks, notamment en mathématiques, codage et tâches multilingues.
Entraîné sur 14,8 billions de tokens diversifiés et intégrant des techniques avancées comme la prédiction multi-tokens, DeepSeek v3 établit de nouveaux standards en modélisation du langage IA. Le modèle prend en charge une fenêtre de contexte de 128K et offre des performances comparables aux modèles propriétaires leaders tout en maintenant des capacités d'inférence efficaces.
DeepSeek v3 combine une architecture MoE massive de 671B paramètres avec des fonctionnalités innovantes comme la prédiction multi-tokens et l'équilibrage de charge sans perte auxiliaire, offrant des performances exceptionnelles sur diverses tâches.
DeepSeek v3 est disponible via notre plateforme de démonstration en ligne et nos services API. Vous pouvez également télécharger les poids du modèle pour un déploiement local.
DeepSeek v3 démontre des performances supérieures en mathématiques, codage, raisonnement et tâches multilingues, obtenant constamment des résultats de premier plan dans les évaluations de benchmark.
DeepSeek v3 prend en charge diverses options de déploiement, y compris les GPU NVIDIA, les GPU AMD et les NPU Huawei Ascend, avec plusieurs options de framework pour des performances optimales.
Oui, DeepSeek v3 prend en charge l'utilisation commerciale sous réserve des conditions de licence du modèle.
DeepSeek v3 surpasse les autres modèles open-source et atteint des performances comparables aux modèles propriétaires leaders sur divers benchmarks.
DeepSeek v3 peut être déployé en utilisant plusieurs frameworks dont SGLang, LMDeploy, TensorRT-LLM, vLLM, et prend en charge les modes d'inférence FP8 et BF16.
DeepSeek v3 dispose d'une fenêtre de contexte de 128K, lui permettant de traiter et comprendre efficacement des séquences d'entrée étendues pour des tâches complexes et du contenu long.
DeepSeek v3 a été pré-entraîné sur 14,8 billions de tokens diversifiés et de haute qualité, suivi d'étapes de Fine-tuning supervisé et d'Apprentissage par renforcement. Le processus d'entraînement était remarquablement stable sans pics de perte irrécupérables.
DeepSeek v3 utilise l'entraînement en précision mixte FP8 et réalise un entraînement MoE inter-nœuds efficace grâce à une co-conception algorithme-framework-matériel, complétant le pré-entraînement avec seulement 2,788M heures GPU H800.