
DeepSeek V3 - Redéfinir les standards d’efficacité en IA
January 13, 2025
DeepSeek V3 : une percée décisive dans l’efficacité de l’IA
Dans une avancée majeure pour la communauté IA, DeepSeek V3 s’impose comme un modèle révolutionnaire qui remet en question notre compréhension traditionnelle de l’efficacité et de la rentabilité de l’entraînement. Cette analyse exhaustive explore comment DeepSeek V3 atteint des performances de pointe tout en réduisant drastiquement les ressources requises.
Innovation architecturale : la puissance du MoE
Au cœur de DeepSeek V3 se trouve une architecture Mixture‑of‑Experts (MoE) sophistiquée, qui transforme en profondeur le fonctionnement des grands modèles de langage. Bien que le modèle compte 671 milliards de paramètres, il n’en active intelligemment que 37 milliards par inférence, marquant un changement de paradigme en matière d’efficacité.
Composants architecturaux clés :
-
Activation intelligente des paramètres
- Engagement sélectif des experts selon la tâche
- Réduction drastique de la charge de calcul
- Maintien d’une qualité de performance élevée malgré moins de paramètres actifs
-
Multi‑head Latent Attention (MLA)
- Capacités renforcées de traitement du contexte
- Empreinte mémoire réduite en inférence
- Mécanismes d’extraction d’information optimisés
Abaisser les barrières de coûts
Les implications financières des innovations de DeepSeek V3 sont considérables :
- Coût d’entraînement : 5,6 M$
- Durée d’entraînement : 57 jours
- Utilisation GPU : 2,788 M d’heures GPU H800
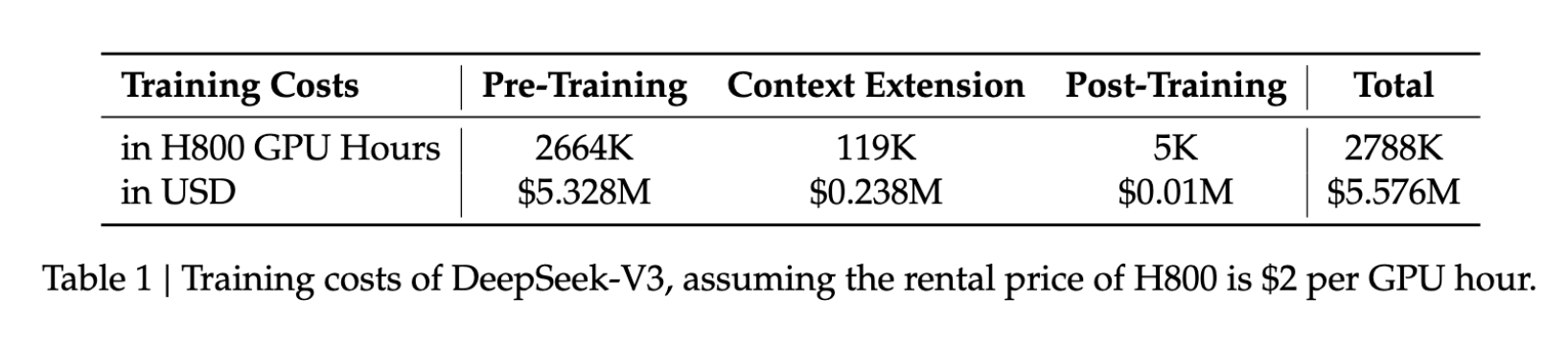
Ces chiffres ne représentent qu’une fraction des ressources habituellement nécessaires pour entraîner des modèles comparables, rendant le développement d’IA avancée plus accessible.
Des performances éloquentes
Malgré son design axé sur l’efficacité, DeepSeek V3 affiche des performances remarquables sur des benchmarks clés :
| Benchmark | Score |
|---|---|
| MMLU | 87,1 % |
| BBH | 87,5 % |
| DROP | 89,0 % |
| HumanEval | 65,2 % |
| MBPP | 75,4 % |
| GSM8K | 89,3 % |
Ces résultats placent DeepSeek V3 au niveau des leaders du marché comme GPT‑4 et Claude 3.5 Sonnet, notamment pour le raisonnement complexe et le code.
Innovations techniques
1. Répartition de charge sans perte auxiliaire
Le modèle introduit une approche novatrice qui maintient des performances optimales sans les inconvénients des mécanismes de perte auxiliaire.
2. Prédiction multi‑token
Grâce à des capacités avancées de prédiction multi‑token, DeepSeek V3 offre :
- Une génération plus rapide
- Une meilleure compréhension contextuelle
- Une efficacité accrue dans le traitement des tokens
Applications pratiques
Les retombées pratiques des capacités de DeepSeek V3 sont vastes :
- Fenêtre de contexte étendue : 128 000 tokens pour l’analyse documentaire
- Vitesse de génération : jusqu’à 90 tokens/s
- Efficience des ressources : coûts de déploiement nettement réduits
L’avenir du développement en IA
DeepSeek V3 est plus qu’une nouvelle version : c’est un changement de cap dans l’approche du développement IA. En démontrant qu’un niveau de performance élite est possible avec bien moins de ressources, le modèle ouvre la voie à :
- L’entrée de plus petites organisations dans le domaine
- Des pratiques de développement plus durables
- Une innovation accélérée en architecture de modèles
Conclusion
DeepSeek V3 illustre la puissance de l’innovation dans le développement IA. En remettant en question les approches conventionnelles d’architecture et d’entraînement, il établit de nouveaux standards d’efficacité tout en conservant des performances de très haut niveau.
« DeepSeek V3 ne se contente pas de repousser les limites de l’IA : il les redéfinit. Son approche révolutionnaire de l’efficacité et des performances fixe un nouveau standard pour toute l’industrie. »