DeepSeek v3 기능
복잡한 추론부터 코드 생성까지 다양한 도메인에 걸쳐 DeepSeek v3의 인상적인 기능을 살펴보세요.

DeepSeek v3는 총 671B 매개변수와 각 토큰에 대해 활성화된 37B 매개변수를 특징으로 하는 AI 언어 모델의 획기적인 발전을 나타냅니다. 혁신적인 MoE(Mixture-of-Experts) 아키텍처를 기반으로 구축된 DeepSeek v3는 효율적인 추론을 유지하면서 다양한 벤치마크에서 최첨단 성능을 제공합니다.
복잡한 추론부터 코드 생성까지 다양한 도메인에 걸쳐 DeepSeek v3의 인상적인 기능을 살펴보세요.
DeepSeek v3가 대규모 언어 모델에서 최고의 선택이 되는 이유를 알아보세요.
DeepSeek v3는 총 671B 매개변수를 갖춘 혁신적인 전문가 혼합 아키텍처를 활용하여 최적의 성능을 위해 각 토큰에 대해 37B 매개변수를 활성화합니다.
14.8조 개의 고품질 토큰으로 사전 훈련된 DeepSeek v3는 다양한 영역에 걸쳐 포괄적인 지식을 보여줍니다.
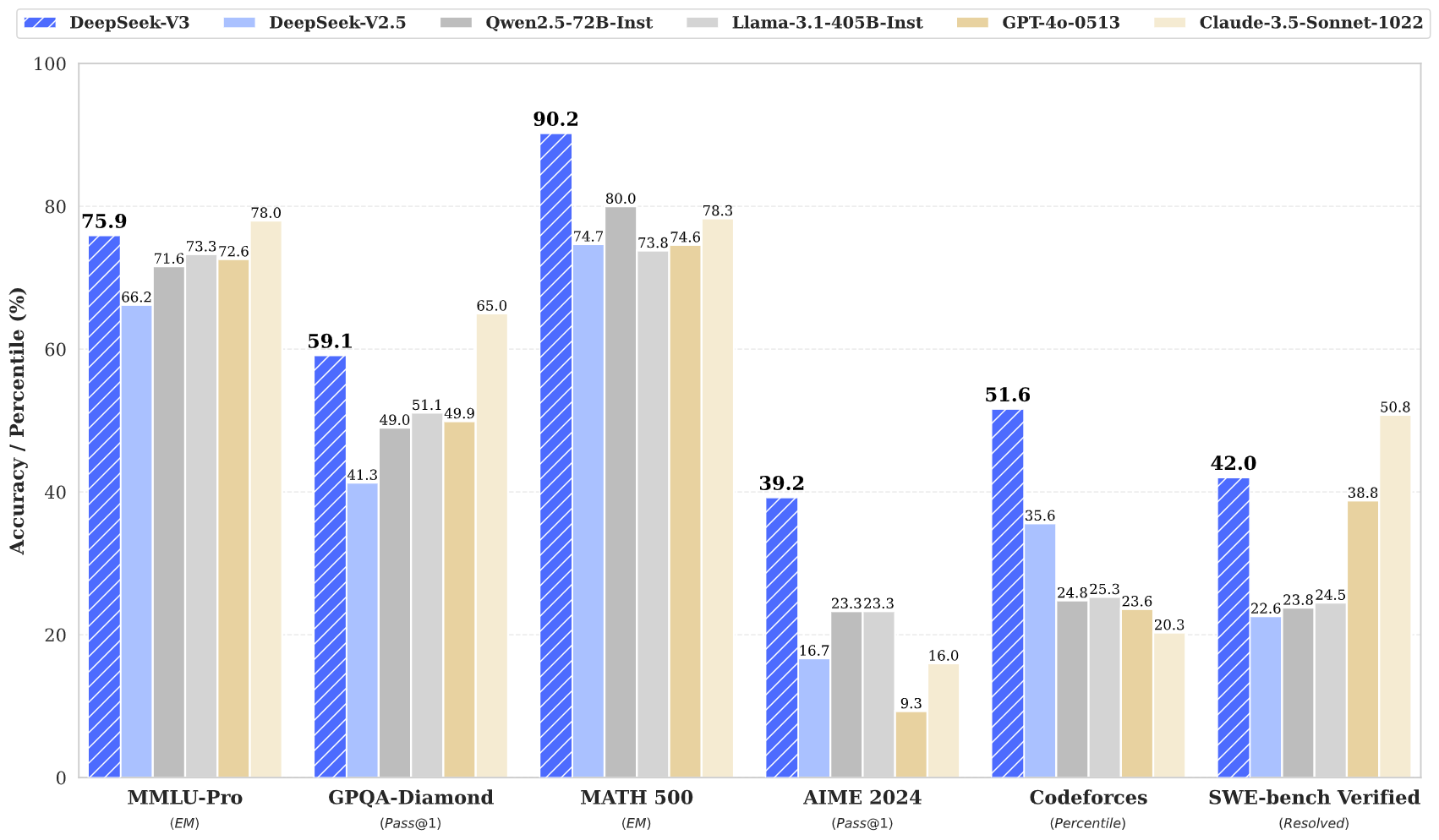
DeepSeek v3는 수학, 코딩, 다국어 작업을 포함한 여러 벤치마크에서 최첨단 결과를 달성합니다.
DeepSeek v3는 큰 크기에도 불구하고 혁신적인 아키텍처 설계를 통해 효율적인 추론 기능을 유지합니다.
128K 컨텍스트 창을 통해 DeepSeek v3는 광범위한 입력 시퀀스를 효과적으로 처리하고 이해할 수 있습니다.
DeepSeek v3에는 향상된 성능과 추론 가속화를 위한 고급 다중 토큰 예측이 통합되어 있습니다.
간단한 3단계로 DeepSeek v3의 강력한 기능에 액세스하세요
텍스트 생성, 코드 완성, 수학적 추론 등 다양한 작업 중에서 선택하세요. DeepSeek v3는 여러 도메인에서 탁월한 성능을 발휘합니다.
프롬프트나 질문을 입력하세요. DeepSeek v3의 고급 아키텍처는 671B 매개변수 모델로 고품질 응답을 보장합니다.
고급 추론과 이해를 보여주는 응답으로 DeepSeek v3의 뛰어난 성능을 경험해 보세요.
DeepSeek v3가 AI 언어 모델 분야를 어떻게 발전시키고 있는지 알아보세요.
DeepSeek v3의 최신 뉴스와 통찰력을 받아보세요.
DeepSeek v3은 총 671B 매개변수를 갖춘 획기적인 전문가 혼합 아키텍처를 특징으로 하는 대규모 언어 모델의 최신 발전을 나타냅니다. 이 혁신적인 모델은 수학, 코딩, 다국어 작업을 포함한 다양한 벤치마크에서 탁월한 성능을 보여줍니다.
14조 8천억 개의 다양한 토큰을 학습하고 멀티 토큰 예측과 같은 고급 기술을 통합한 DeepSeek v3는 AI 언어 모델링의 새로운 표준을 설정합니다. 이 모델은 128K 컨텍스트 창을 지원하고 효율적인 추론 기능을 유지하면서 주요 비공개 소스 모델에 필적하는 성능을 제공합니다.
DeepSeek v3는 대규모 671B 매개변수 MoE 아키텍처와 멀티 토큰 예측 및 보조 무손실 로드 밸런싱과 같은 혁신적인 기능을 결합하여 다양한 작업에서 탁월한 성능을 제공합니다.
DeepSeek v3는 온라인 데모 플랫폼과 API 서비스를 통해 제공됩니다. 로컬 배포를 위한 모델 가중치를 다운로드할 수도 있습니다.
DeepSeek v3는 수학, 코딩, 추론 및 다국어 작업에서 뛰어난 성능을 보여주며 벤치마크 평가에서 지속적으로 최고의 결과를 달성합니다.
DeepSeek v3는 최적의 성능을 위한 여러 프레임워크 옵션과 함께 NVIDIA GPU, AMD GPU 및 Huawei Ascend NPU를 포함한 다양한 배포 옵션을 지원합니다.
예, DeepSeek v3는 모델 라이선스 조건에 따라 상업적 사용을 지원합니다.
DeepSeek v3는 다른 오픈 소스 모델보다 성능이 뛰어나며 다양한 벤치마크에서 주요 폐쇄 소스 모델과 비슷한 성능을 달성합니다.
DeepSeek v3은 SGLang, LMDeploy, TensorRT-LLM, vLLM을 포함한 여러 프레임워크를 사용하여 배포할 수 있으며 FP8 및 BF16 추론 모드를 모두 지원합니다.
DeepSeek v3는 128K 컨텍스트 창을 갖추고 있어 복잡한 작업과 긴 형식의 콘텐츠에 대해 광범위한 입력 시퀀스를 효과적으로 처리하고 이해할 수 있습니다.
DeepSeek v3는 14조 8천억 개의 다양한 고품질 토큰에 대해 사전 교육을 받은 후 감독 미세 조정 및 강화 학습 단계를 거쳤습니다. 훈련 과정은 복구할 수 없는 손실 급증 없이 매우 안정적이었습니다.
DeepSeek v3는 FP8 혼합 정밀 교육을 활용하고 알고리즘-프레임워크-하드웨어 공동 설계를 통해 효율적인 교차 노드 MoE 교육을 달성하여 단 2788M H800 GPU 시간으로 사전 교육을 완료합니다.


