
DeepSeek V3 — AI 효율의 새로운 표준을 재정의하다
January 13, 2025
DeepSeek V3: AI 효율성에서의 획기적 돌파구
AI 커뮤니티에 큰 전환점을 가져온 개발로서, DeepSeek V3는 학습 효율성과 비용에 대한 기존 인식을 뒤흔드는 혁신적 모델로 부상했습니다. 본 글은 DeepSeek V3가 자원 요구 사항을 대폭 줄이면서도 최첨단 성능을 달성하는 방식을 심층 분석합니다.
아키텍처 혁신: MoE의 힘
DeepSeek V3의 핵심에는 정교한 Mixture‑of‑Experts(MoE) 아키텍처가 있습니다. 총 6,710억의 파라미터를 보유하면서도, 추론 시에는 370억만을 지능적으로 활성화하여 효율성 면에서 패러다임 전환을 이룹니다.
핵심 아키텍처 구성 요소:
-
지능형 파라미터 활성화
- 작업 요구 사항에 따른 선택적 전문가 활성화
- 계산 오버헤드의 대폭 감소
- 더 적은 활성 파라미터로도 높은 품질 유지
-
Multi‑head Latent Attention(MLA)
- 문맥 처리 능력 강화
- 추론 시 메모리 사용량 감소
- 정보 추출 메커니즘 최적화
비용 장벽 허물기
DeepSeek V3의 혁신은 비용 측면에서 두드러진 효과를 보여줍니다:
- 학습 비용: $5.6M
- 학습 기간: 57일
- GPU 사용량: H800 기준 278.8만 시간
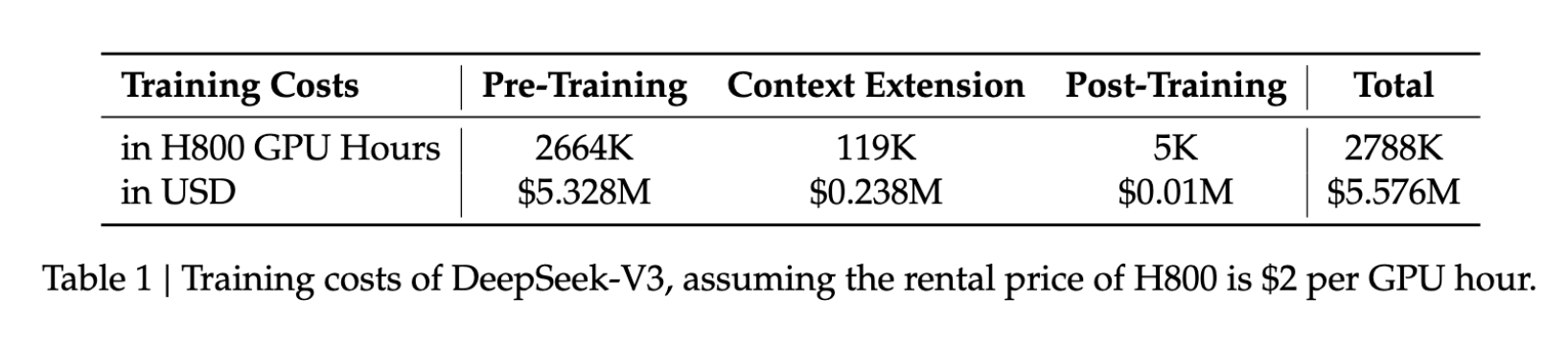
동급 모델 대비 위 수치는 필요한 자원의 일부분에 불과하며, 첨단 AI 개발을 더 많은 조직에 개방합니다.
수치로 증명된 성능
효율 중심 설계에도 불구하고, DeepSeek V3는 주요 벤치마크에서 탁월한 성능을 보입니다:
| 벤치마크 | 점수 |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
이는 DeepSeek V3가 복잡한 추론과 코딩 과제에서 GPT‑4, Claude 3.5 Sonnet과 어깨를 나란히 한다는 것을 보여줍니다.
기술적 혁신
1. 보조 손실 없는 부하 분산
보조 손실 메커니즘의 단점을 회피하면서도 최적 성능을 유지하는 새로운 부하 분산 접근을 도입.
2. 멀티 토큰 예측
고도화된 멀티 토큰 예측 능력으로 다음을 달성:
- 더 빠른 텍스트 생성
- 강화된 문맥 이해
- 효율적인 토큰 처리
실용적 적용
DeepSeek V3의 역량은 실무에서 폭넓은 영향을 미칩니다:
- 확장 컨텍스트 윈도우: 128,000 토큰으로 포괄적 문서 분석
- 생성 속도: 최대 90 토큰/초
- 자원 효율성: 배포 비용 대폭 절감
AI 개발의 미래
DeepSeek V3는 단순한 신규 릴리스가 아니라, AI 개발 접근의 근본적 변화입니다. 훨씬 적은 자원으로도 최상급 성능을 달성 가능함을 보여주며, 다음의 가능성을 엽니다:
- 중소 조직의 AI 진입 확대
- 더욱 지속 가능한 개발 관행
- 모델 아키텍처 혁신의 가속화
결론
DeepSeek V3는 AI 개발에서 혁신적 사고의 힘을 입증합니다. 전통적 아키텍처와 학습 방식을 뛰어넘어, 엘리트급 성능을 유지하면서 효율성의 새로운 기준을 제시합니다.
"DeepSeek V3는 AI 가능성의 경계를 넓히는 데 그치지 않고, 그 경계를 재정의합니다. 효율과 성능에 대한 혁신적 접근은 업계 전체의 새로운 표준을 수립합니다."