Возможности DeepSeek v3
Исследуйте впечатляющие возможности DeepSeek v3 в различных областях — от сложных рассуждений до генерации кода.
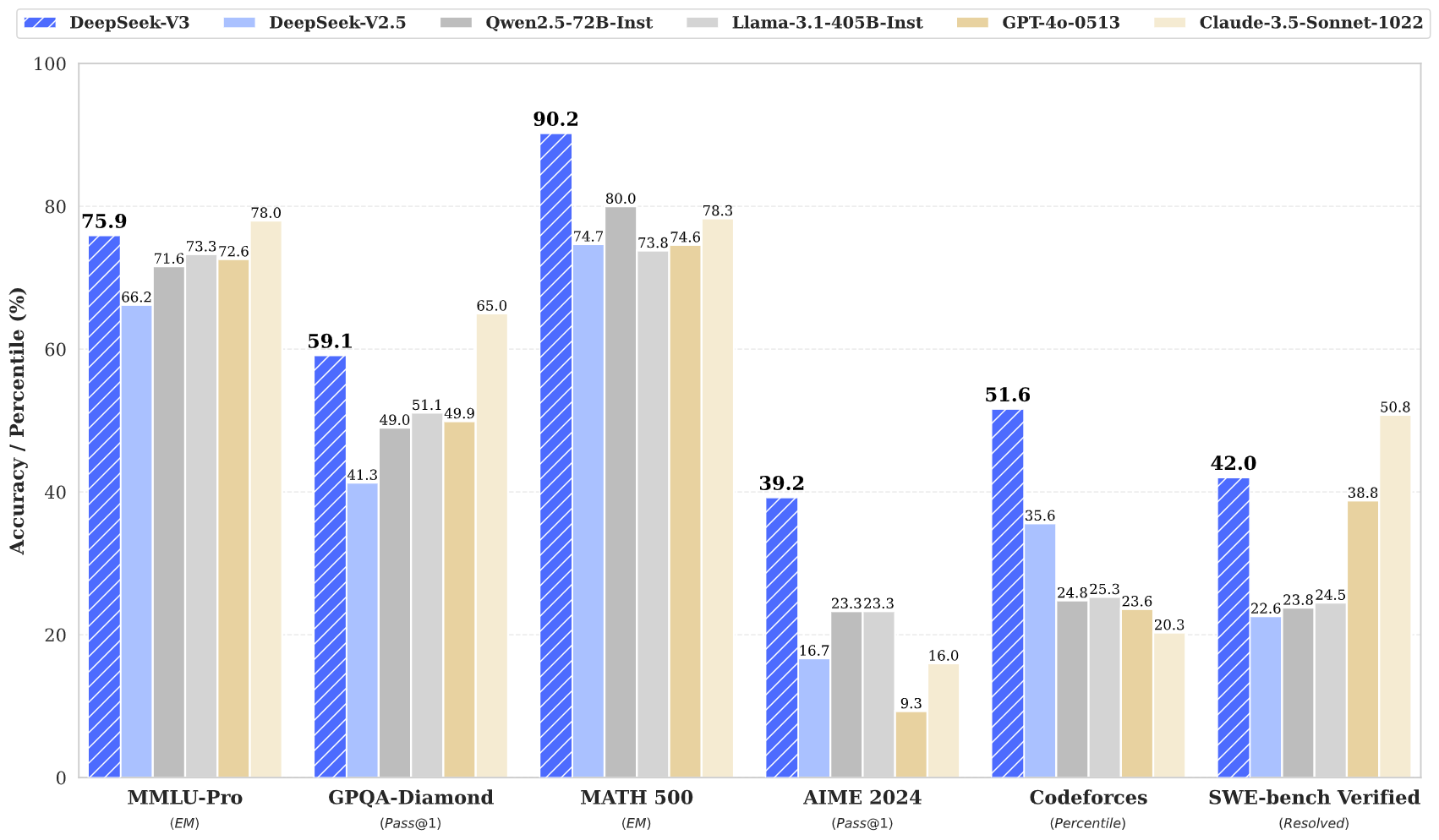

DeepSeek v3 представляет собой крупный прорыв в языковых моделях искусственного интеллекта: общее количество параметров составляет 671 млрд, из которых 37 млрд активировано для каждого токена. DeepSeek v3, построенный на инновационной архитектуре Mixture-of-Experts (MoE), обеспечивает высочайшую производительность в различных тестах, сохраняя при этом эффективный вывод.
Исследуйте впечатляющие возможности DeepSeek v3 в различных областях — от сложных рассуждений до генерации кода.
Узнайте, что делает DeepSeek v3 лучшим выбором для больших языковых моделей
DeepSeek v3 использует инновационную архитектуру Mixture-of-Experts с общим количеством параметров 671B, активируя 37B параметров для каждого токена для оптимальной производительности.
DeepSeek v3, предварительно обученный на 14,8 триллионах высококачественных токенов, демонстрирует обширные знания в различных областях.
DeepSeek v3 достигает самых современных результатов в нескольких тестах, включая математику, программирование и многоязычные задачи.
Несмотря на свой большой размер, DeepSeek v3 поддерживает эффективные возможности вывода благодаря инновационной архитектуре.
Благодаря контекстному окну размером 128 КБ DeepSeek v3 может эффективно обрабатывать и понимать обширные входные последовательности.
DeepSeek v3 включает расширенное прогнозирование нескольких токенов для повышения производительности и ускорения вывода.
Получите доступ к возможностям DeepSeek v3 за три простых шага
Выбирайте из различных задач, включая генерацию текста, завершение кода и математические рассуждения. DeepSeek v3 превосходно работает в нескольких доменах.
Введите подсказку или вопрос. Усовершенствованная архитектура DeepSeek v3 обеспечивает высококачественные ответы благодаря модели параметров 671B.
Ощутите превосходную производительность DeepSeek v3 благодаря ответам, демонстрирующим продвинутые рассуждения и понимание.
Узнайте, как DeepSeek v3 продвигает область языковых моделей искусственного интеллекта
Будьте в курсе последних новостей и идей DeepSeek v3.

DeepSeek V3.1 — Комплексный разбор новейшей открытой модели ИИ

DeepSeek‑V3‑0324 — комплексные улучшения всех возможностей

DeepSeek V3 — переопределение стандартов эффективности ИИ
DeepSeek v3 представляет собой последнее достижение в области больших языковых моделей, отличающееся революционной архитектурой Mixture-of-Experts с общим числом параметров 671B. Эта инновационная модель демонстрирует исключительную производительность в различных тестах, включая математику, программирование и многоязычные задачи.
DeepSeek v3, обученный на 14,8 триллионах разнообразных токенов и включающий передовые методы, такие как прогнозирование нескольких токенов, устанавливает новые стандарты в языковом моделировании искусственного интеллекта. Модель поддерживает контекстное окно размером 128 КБ и обеспечивает производительность, сравнимую с ведущими моделями с закрытым исходным кодом, сохраняя при этом эффективные возможности вывода.
DeepSeek v3 сочетает в себе массивную архитектуру MoE с 671 байтами параметров и инновационными функциями, такими как прогнозирование нескольких токенов и балансировку нагрузки без вспомогательных потерь, обеспечивая исключительную производительность при выполнении различных задач.
DeepSeek v3 доступен через нашу демонстрационную онлайн-платформу и службы API. Вы также можете загрузить веса модели для локального развертывания.
DeepSeek v3 демонстрирует превосходную производительность в математике, кодировании, рассуждениях и многоязычных задачах, стабильно достигая лучших результатов в тестовых тестах.
DeepSeek v3 поддерживает различные варианты развертывания, включая графические процессоры NVIDIA, графические процессоры AMD и NPU Huawei Ascend, а также несколько вариантов инфраструктуры для оптимальной производительности.
Да, DeepSeek v3 поддерживает коммерческое использование в соответствии с условиями типовой лицензии.
DeepSeek v3 превосходит другие модели с открытым исходным кодом и достигает производительности, сравнимой с ведущими моделями с закрытым исходным кодом в различных тестах.
DeepSeek v3 можно развернуть с использованием нескольких платформ, включая SGLang, LMDeploy, TensorRT-LLM, vLLM, и поддерживает режимы вывода FP8 и BF16.
DeepSeek v3 имеет контекстное окно размером 128 КБ, что позволяет ему эффективно обрабатывать и понимать обширные последовательности ввода для сложных задач и длинного контента.
DeepSeek v3 прошел предварительное обучение на 14,8 триллионах разнообразных и высококачественных токенов, после чего прошли этапы контролируемой точной настройки и обучения с подкреплением. Процесс обучения был удивительно стабильным, без всплесков невосполнимых потерь.
DeepSeek v3 использует обучение смешанной точности FP8 и обеспечивает эффективное межузловое обучение MoE за счет совместного проектирования алгоритма, платформы и оборудования, завершая предварительное обучение всего за 2,788 млн часов графического процессора H800.