
DeepSeek V3 — переопределение стандартов эффективности ИИ
January 13, 2025
DeepSeek V3: прорыв в эффективности ИИ
Важное событие для сообщества ИИ: DeepSeek V3 — революционная модель, бросающая вызов традиционным представлениям об эффективности и стоимости обучения. В этом обзоре рассматривается, как DeepSeek V3 достигает результатов уровня state‑of‑the‑art при радикальном снижении ресурсных требований.
Архитектурные инновации: сила MoE
В основе DeepSeek V3 — изощрённая архитектура Mixture‑of‑Experts (MoE), радикально меняющая работу больших языковых моделей. При внушительных 671 млрд параметров модель задействует на инференсе лишь 37 млрд, что является сменой парадигмы в вопросах эффективности.
Ключевые архитектурные компоненты:
-
Интеллектуальная активация параметров
- Выборочное задействование экспертов по требованию задачи
- Существенное снижение вычислительных затрат
- Сохранение качества при меньшем числе активных параметров
-
Multi‑head Latent Attention (MLA)
- Улучшенная обработка контекста
- Меньшее потребление памяти в инференсе
- Оптимизированные механизмы извлечения информации
Разрушая ценовые барьеры
Финансовые эффекты инноваций DeepSeek V3 впечатляют:
- Стоимость обучения: $5.6 млн
- Длительность: 57 дней
- GPU‑время: 2.788 млн часов на H800
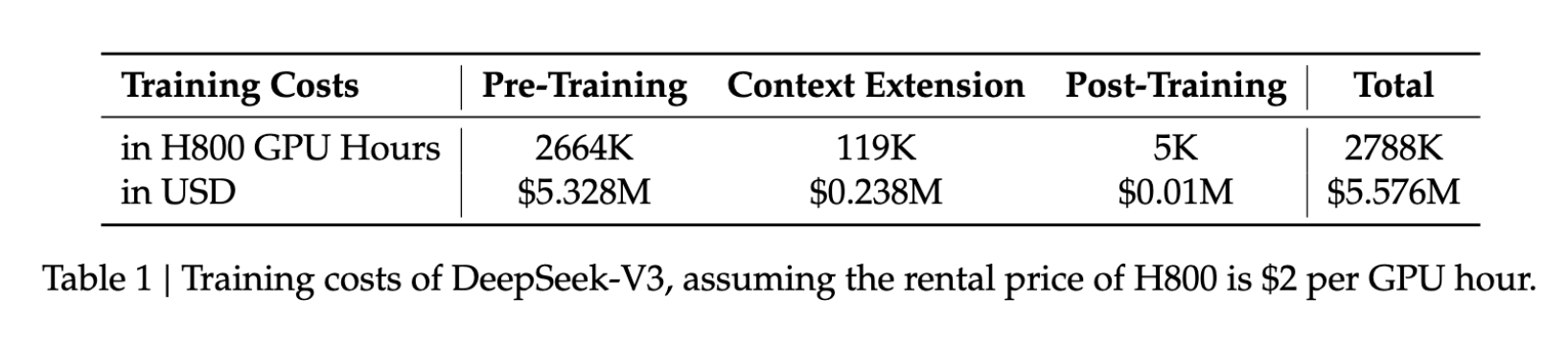
Эти цифры — лишь малая доля ресурсов, обычно требуемых для сопоставимых моделей, что делает продвинутую разработку ИИ доступнее для большего числа организаций.
Производительность, говорящая сама за себя
Несмотря на акцент на эффективности, DeepSeek V3 демонстрирует выдающиеся результаты на ключевых бенчмарках:
| Бенчмарк | Балл |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
Эти результаты ставят DeepSeek V3 в один ряд с лидерами отрасли, такими как GPT‑4 и Claude 3.5 Sonnet, особенно в задачах сложного рассуждения и программирования.
Технические новшества
1. Балансировка нагрузки без auxiliary loss
Новый подход к распределению нагрузки, поддерживающий оптимальную производительность без недостатков вспомогательных функций потерь.
2. Прогнозирование нескольких токенов
Благодаря расширенной многотокеновой предикции DeepSeek V3 обеспечивает:
- Более быструю текстогенерацию
- Лучшее понимание контекста
- Более эффективную обработку токенов
Практическое применение
Широкий спектр практических эффектов:
- Расширённое контекстное окно: 128 000 токенов для полноценного анализа документов
- Скорость генерации: до 90 токенов/с
- Ресурсоэффективность: заметно сниженные эксплуатационные затраты
Будущее разработки ИИ
DeepSeek V3 — не просто очередной релиз; это кардинальный сдвиг в подходах к разработке ИИ. Показав, что элитная производительность достижима при куда меньших ресурсах, модель открывает дорогу:
- Входу меньших организаций в индустрию
- Более устойчивым практикам разработки
- Ускорению инноваций в архитектуре моделей
Заключение
DeepSeek V3 — наглядное подтверждение силы инновационного мышления. Отказываясь от конвенциональных подходов к архитектуре и обучению, модель задаёт новые стандарты эффективности при сохранении высочайшей производительности.
«DeepSeek V3 не просто расширяет границы возможного в ИИ — он их переопределяет. Революционный подход к эффективности и производительности задаёт новый стандарт для всей индустрии».