Capacidades de DeepSeek v3
Explore las impresionantes capacidades de DeepSeek v3 en diferentes dominios, desde el razonamiento complejo hasta la generación de código
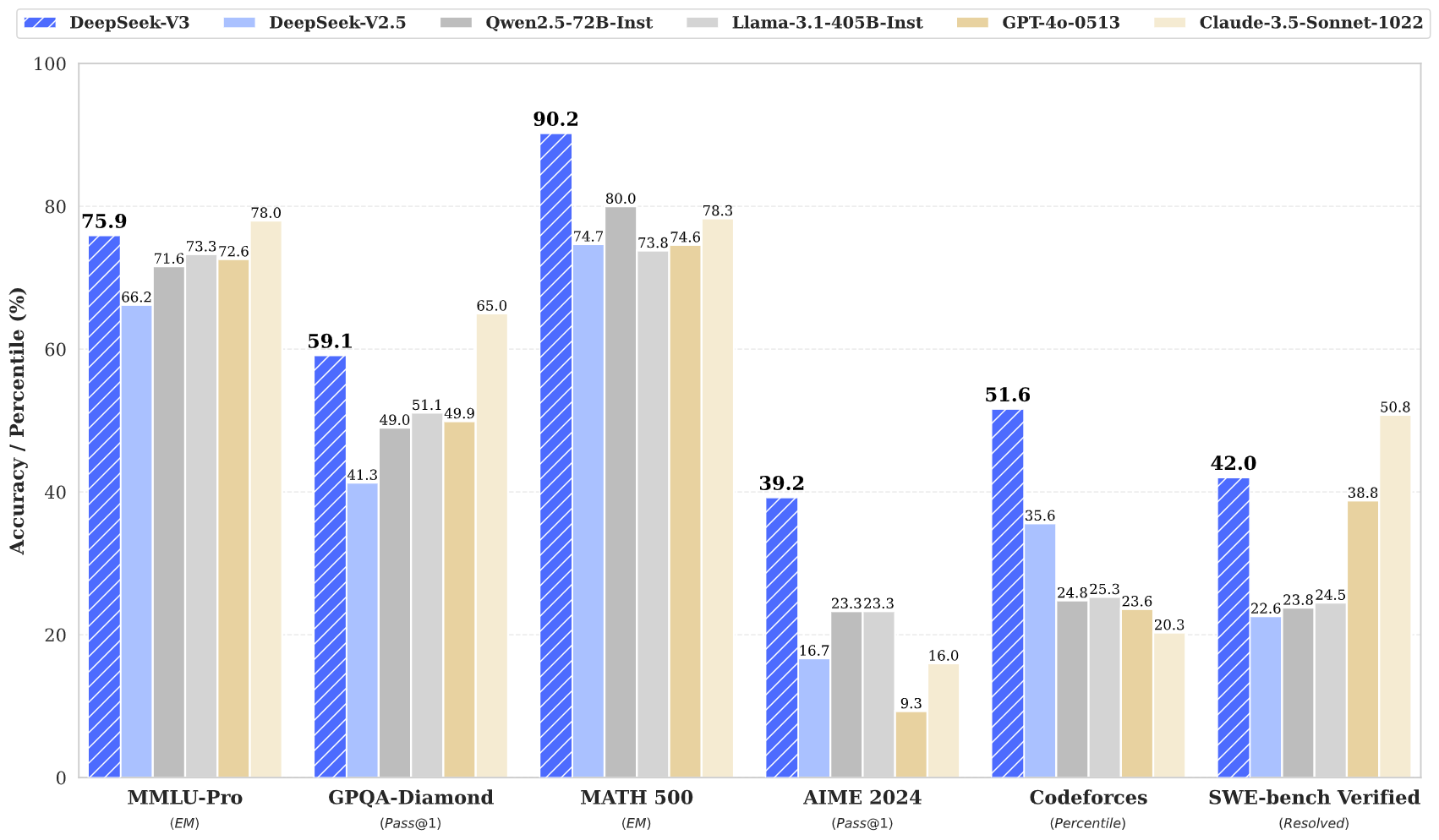

DeepSeek v3 representa un gran avance en los modelos de lenguaje de IA, con 671B parámetros totales y 37B activados para cada token. Construido sobre la innovadora arquitectura Mixture-of-Experts (MoE), DeepSeek v3 ofrece un rendimiento de última generación en varios puntos de referencia mientras mantiene una inferencia eficiente.
Explore las impresionantes capacidades de DeepSeek v3 en diferentes dominios, desde el razonamiento complejo hasta la generación de código
Descubra qué hace de DeepSeek v3 una opción líder en modelos de lenguaje grandes
DeepSeek v3 utiliza una innovadora arquitectura Mixture-of-Experts con 671B parámetros totales, activando 37B parámetros para cada token para un rendimiento óptimo.
Pre-entrenado con 14.8 billones de tokens de alta calidad, DeepSeek v3 demuestra un conocimiento integral en varios dominios.
DeepSeek v3 logra resultados de última generación en múltiples puntos de referencia, incluyendo matemáticas, programación y tareas multilingües.
A pesar de su gran tamaño, DeepSeek v3 mantiene capacidades de inferencia eficientes a través de un diseño innovador de arquitectura.
Con una ventana de contexto de 128K, DeepSeek v3 puede procesar y comprender secuencias de entrada extensas de manera efectiva.
DeepSeek v3 incorpora Predicción Multi-Token avanzada para mejorar el rendimiento y acelerar la inferencia.
Acceda al poder de DeepSeek v3 en tres simples pasos
Seleccione entre varias tareas, incluyendo generación de texto, completado de código y razonamiento matemático. DeepSeek v3 sobresale en múltiples dominios.
Introduzca su prompt o pregunta. La arquitectura avanzada de DeepSeek v3 asegura respuestas de alta calidad con su modelo de 671B parámetros.
Experimente el rendimiento superior de DeepSeek v3 con respuestas que demuestran razonamiento y comprensión avanzados.
Descubra cómo DeepSeek v3 está avanzando en el campo de los modelos de lenguaje de IA
Manténgase actualizado con las últimas noticias y conocimientos de DeepSeek v3

DeepSeek V3.1 — Análisis completo del último modelo de IA de código abierto

DeepSeek-V3-0324 - Mejoras integrales en todas las capacidades

DeepSeek V3 - Redefiniendo los estándares de eficiencia en IA
DeepSeek v3 representa el último avance en modelos de lenguaje grandes, presentando una revolucionaria arquitectura Mixture-of-Experts con 671B parámetros totales. Este modelo innovador demuestra un rendimiento excepcional en varios puntos de referencia, incluyendo matemáticas, programación y tareas multilingües.
Entrenado con 14.8 billones de tokens diversos e incorporando técnicas avanzadas como Multi-Token Prediction, DeepSeek v3 establece nuevos estándares en el modelado de lenguaje de IA. El modelo admite una ventana de contexto de 128K y ofrece un rendimiento comparable a los modelos de código cerrado líderes mientras mantiene capacidades de inferencia eficientes.
DeepSeek v3 combina una masiva arquitectura MoE de 671B parámetros con características innovadoras como Predicción Multi-Token y equilibrio de carga sin pérdidas auxiliares, ofreciendo un rendimiento excepcional en varias tareas.
DeepSeek v3 está disponible a través de nuestra plataforma de demostración en línea y servicios API. También puede descargar los pesos del modelo para implementación local.
DeepSeek v3 demuestra un rendimiento superior en matemáticas, programación, razonamiento y tareas multilingües, logrando consistentemente resultados superiores en evaluaciones de referencia.
DeepSeek v3 admite varias opciones de implementación, incluyendo GPUs NVIDIA, GPUs AMD y NPUs Huawei Ascend, con múltiples opciones de framework para un rendimiento óptimo.
Sí, DeepSeek v3 admite uso comercial sujeto a los términos de licencia del modelo.
DeepSeek v3 supera a otros modelos de código abierto y logra un rendimiento comparable a los modelos de código cerrado líderes en varios puntos de referencia.
DeepSeek v3 puede implementarse usando múltiples frameworks incluyendo SGLang, LMDeploy, TensorRT-LLM, vLLM, y admite modos de inferencia FP8 y BF16.
DeepSeek v3 cuenta con una ventana de contexto de 128K, permitiéndole procesar y comprender secuencias de entrada extensas de manera efectiva para tareas complejas y contenido de forma larga.
DeepSeek v3 fue pre-entrenado con 14.8 billones de tokens diversos y de alta calidad, seguido por etapas de Ajuste Fino Supervisado y Aprendizaje por Refuerzo. El proceso de entrenamiento fue notablemente estable sin picos de pérdida irrecuperables.
DeepSeek v3 utiliza entrenamiento de precisión mixta FP8 y logra un entrenamiento MoE eficiente entre nodos a través del co-diseño algoritmo-framework-hardware, completando el pre-entrenamiento con solo 2.788M horas de GPU H800.