
DeepSeek V3 — إعادة تعريف معايير كفاءة الذكاء الاصطناعي
January 13, 2025
DeepSeek V3: اختراق نوعي في كفاءة الذكاء الاصطناعي
في تطور فارق لمجتمع الذكاء الاصطناعي، برز DeepSeek V3 كنموذج ثوري يتحدى الفهم التقليدي لكفاءة التدريب وتكاليفه. تستعرض هذه المقالة كيف يحقق DeepSeek V3 أداءً متقدمًا مع تقليل كبير في متطلبات الموارد.
ابتكار معماري: قوة بنية MoE
يعتمد DeepSeek V3 في جوهره على بنية Mixture‑of‑Experts (MoE) المتقدمة، التي تغيّر بشكل جذري طريقة عمل النماذج اللغوية الكبيرة. فرغم امتلاكه 671 مليار باراميتر، فإنه يفعّل بذكاء فقط 37 مليارًا لكل عملية استدلال، ما يمثل نقلة نوعية في الكفاءة.
المكونات المعمارية الأساسية:
-
التفعيل الذكي للباراميترات
- إشراك انتقائي للخبراء حسب متطلبات المهمة
- خفض كبير في العبء الحاسوبي
- الحفاظ على جودة الأداء رغم انخفاض عدد الباراميترات المفعّلة
-
Multi‑head Latent Attention (MLA)
- قدرات محسّنة لمعالجة السياق
- تقليل استهلاك الذاكرة أثناء الاستدلال
- آليات محسّنة لاستخلاص المعلومات
كسر الحواجز الاقتصادية
لابتكارات DeepSeek V3 آثار مالية لافتة:
- تكلفة التدريب: 5.6 مليون دولار
- مدة التدريب: 57 يومًا
- زمن استخدام GPU: 2.788 مليون ساعة على H800
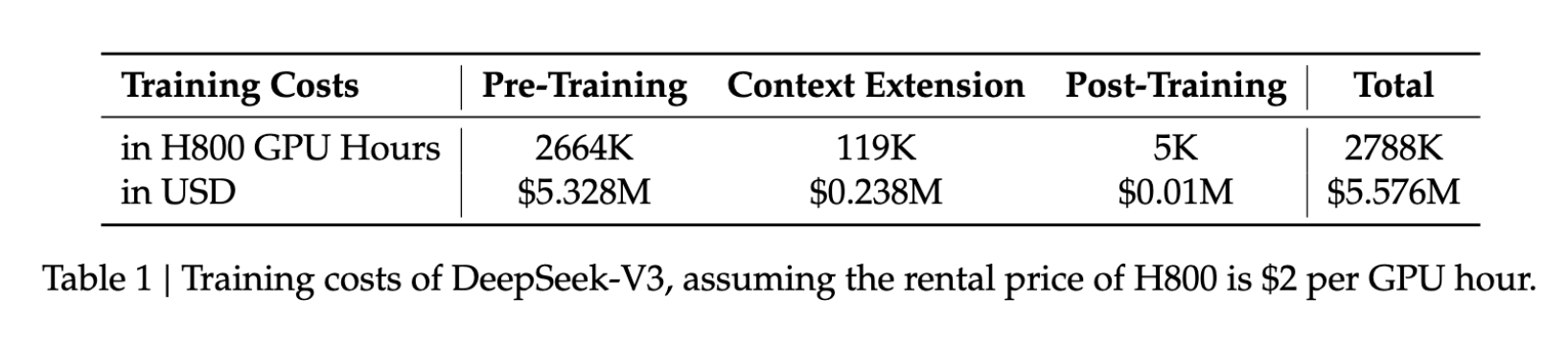
تمثل هذه الأرقام جزءًا بسيطًا من الموارد المطلوبة عادةً لتدريب نماذج مماثلة، مما يجعل تطوير الذكاء الاصطناعي المتقدم أكثر إتاحة للعديد من المؤسسات.
أداء يتحدث عن نفسه
على الرغم من تركيزه على الكفاءة، يحقق DeepSeek V3 نتائج مميزة عبر معايير رئيسية:
| المعيار | النتيجة |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
تضع هذه النتائج DeepSeek V3 في مصاف النماذج الرائدة مثل GPT‑4 وClaude 3.5 Sonnet، خصوصًا في مهام الاستدلال المعقد والبرمجة.
ابتكارات تقنية
1. موازنة أحمال بلا خسارة مساعدة
نهج جديد يحافظ على الأداء الأمثل دون سلبيات آليات الخسارة المساعدة.
2. تنبؤ متعدد الرموز
بفضل قدرات متقدمة في التنبؤ متعدد الرموز، يحقق DeepSeek V3:
- سرعة أعلى في توليد النصوص
- فهمًا سياقيًا أفضل
- كفاءة أعلى في معالجة الرموز
تطبيقات عملية
لتأثيرات العملية واسعة:
- نافذة سياق ممتدة: 128,000 رمزًا لتحليل شامل للمستندات
- سرعة التوليد: حتى 90 رمزًا/ثانية
- كفاءة الموارد: انخفاض ملحوظ في تكاليف النشر
مستقبل تطوير الذكاء الاصطناعي
لا يُعد DeepSeek V3 مجرد إصدار جديد؛ بل يشير إلى تحول جذري في مقاربات تطوير الذكاء الاصطناعي. إذ يثبت أنه بالإمكان تحقيق أداء رفيع مع موارد أقل بكثير، مما يمهّد الطريق لـ:
- دخول مؤسسات أصغر إلى المجال
- ممارسات تطوير أكثر استدامة
- تسريع الابتكار في هندسة النماذج
الخلاصة
يمثل DeepSeek V3 برهانًا على قوة التفكير الابتكاري في تطوير الذكاء الاصطناعي. ومن خلال كسر القوالب التقليدية في البنية والتدريب، يضع معايير جديدة للكفاءة مع الحفاظ على أداءٍ من الطراز الأول.
"لا يكتفي DeepSeek V3 بدفع حدود الممكن في الذكاء الاصطناعي—بل يعيد تعريفها. إن نهجه الثوري في الكفاءة والأداء يضع معيارًا جديدًا للصناعة بأسرها."