
DeepSeek V3 —— 重新定義 AI 效率標準
January 13, 2025
DeepSeek V3:AI 效率的顛覆性突破
在 AI 社群的一項里程碑式進展中,DeepSeek V3 以革命性姿態現身,挑戰我們對模型訓練效率與成本效益的傳統認知。本文將系統解析 DeepSeek V3 如何在顯著降低資源需求的同時,仍能達到業界前沿的表現。
架構創新:MoE 的力量
DeepSeek V3 的核心採用精妙的 Mixture‑of‑Experts(MoE) 架構,從根本改變大型語言模型的運作方式。儘管模型擁有 6710 億參數,但每次推論僅智慧地啟用 370 億參數,在效率上實現範式轉移。
關鍵架構元件:
-
參數的智慧啟用
- 依任務需求選擇性啟用專家
- 顯著降低計算開銷
- 在較少啟用參數下仍維持高品質輸出
-
Multi‑head Latent Attention(MLA)
- 增強脈絡處理能力
- 推論階段佔用更少記憶體
- 更優化的資訊擷取機制
打破成本門檻
DeepSeek V3 的創新帶來可觀的成本效益:
- 訓練成本:$5.6M
- 訓練時長:57 天
- GPU 使用量:278.8 萬小時(H800)
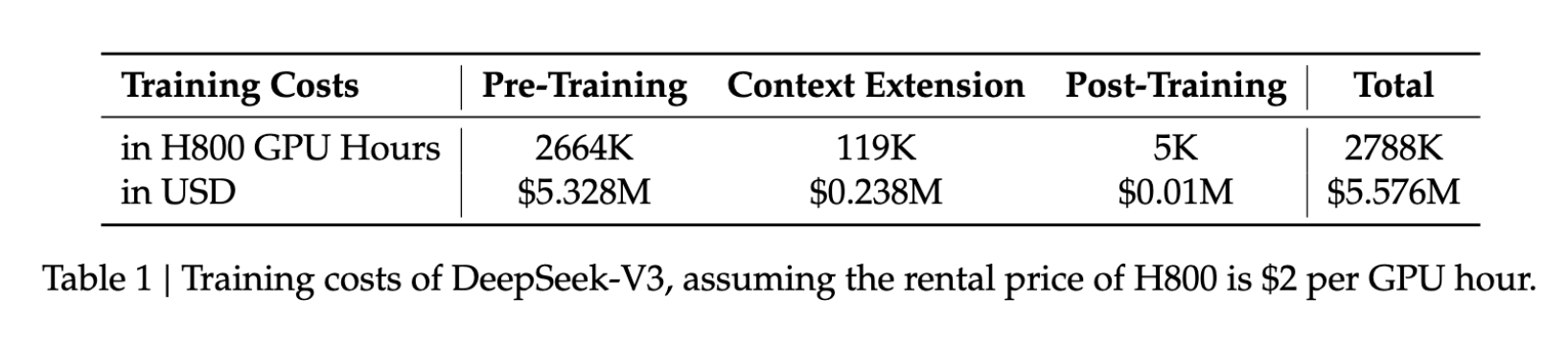
相較同量級模型,上述數字僅為其所需資源的一小部分,讓高階 AI 開發對更多組織更加觸手可及。
亮眼的效能表現
在追求效率的同時,DeepSeek V3 仍於關鍵基準上展現卓越成績:
| Benchmark | 分數 |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
上述結果顯示,DeepSeek V3 與 GPT‑4、Claude 3.5 Sonnet 等業界領先模型比肩,尤其在複雜推理與程式設計任務上競爭力十足。
技術創新
1. 無輔助損失的負載平衡
導入全新負載平衡策略,避免傳統 auxiliary loss 的副作用,同時維持最佳表現。
2. 多 Token 預測
透過先進的多 Token 預測能力,DeepSeek V3 能夠:
- 更快地生成文本
- 更強的脈絡理解
- 更高效的 Token 處理
實務應用價值
DeepSeek V3 的能力在實務中影響深遠:
- 超長脈絡:128,000 tokens,支援全面的文件分析
- 生成速度:最高 90 tokens/s
- 資源效率:顯著降低部署成本
AI 開發的新篇章
DeepSeek V3 不只是版本升級;它代表 AI 開發範式的轉變。其證明在大幅減少資源投入的前提下,仍可達到頂尖效能,為以下方向開啟新可能:
- 更多中小型組織投入 AI 領域
- 更具永續性的開發實踐
- 模型架構創新的加速
結語
DeepSeek V3 詮釋了創新思維在 AI 開發中的力量。藉由突破傳統架構與訓練方法,它在確保精英級表現的同時,樹立效率新標竿。
「DeepSeek V3 不僅推進了 AI 的可能邊界——更重新定義了這些邊界。其在效率與性能上的革命性方法,為整個產業樹立了新標準。」