
DeepSeek V3 – Redefinindo os padrões de eficiência em IA
January 13, 2025
DeepSeek V3: um avanço transformador na eficiência da IA
Em um desenvolvimento marcante para a comunidade de IA, o DeepSeek V3 surge como um modelo que desafia a compreensão tradicional sobre eficiência e custo de treinamento. Esta análise abrangente explora como o DeepSeek V3 atinge desempenho de ponta enquanto reduz drasticamente os requisitos de recursos.
Inovação arquitetural: o poder do MoE
No cerne do DeepSeek V3 está a sofisticada arquitetura Mixture‑of‑Experts (MoE), que transforma fundamentalmente a operação de grandes modelos de linguagem. Embora o modelo conte com 671 bilhões de parâmetros, ele ativa de forma inteligente apenas 37 bilhões por inferência, representando uma mudança de paradigma em eficiência.
Componentes arquiteturais chave:
-
Ativação inteligente de parâmetros
- Engajamento seletivo de especialistas conforme a tarefa
- Redução drástica da carga computacional
- Manutenção da qualidade mesmo com menos parâmetros ativos
-
Multi‑head Latent Attention (MLA)
- Melhoria no processamento de contexto
- Menor uso de memória durante a inferência
- Mecanismos otimizados de extração de informação
Quebrando barreiras de custo
As implicações financeiras das inovações do DeepSeek V3 são impressionantes:
- Custo de treinamento: US$ 5,6 milhões
- Duração do treinamento: 57 dias
- Uso de GPU: 2,788 milhões de horas de GPU H800
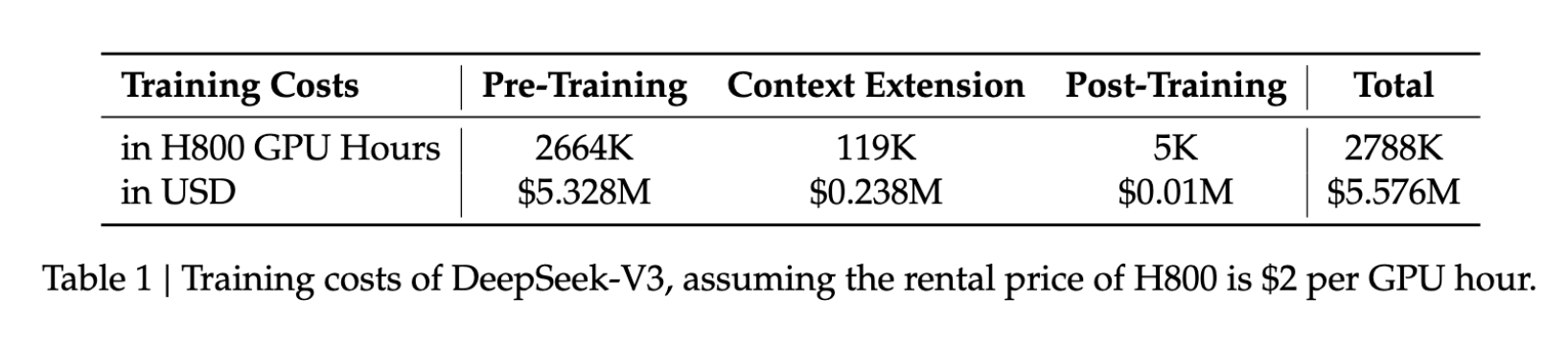
Em perspectiva, esses números representam uma fração dos recursos normalmente exigidos por modelos comparáveis, tornando o desenvolvimento de IA avançada mais acessível.
Desempenho que fala por si
Apesar do foco em eficiência, o DeepSeek V3 apresenta desempenho excepcional em benchmarks-chave:
| Benchmark | Pontuação |
|---|---|
| MMLU | 87,1% |
| BBH | 87,5% |
| DROP | 89,0% |
| HumanEval | 65,2% |
| MBPP | 75,4% |
| GSM8K | 89,3% |
Esses resultados posicionam o DeepSeek V3 ao lado de líderes como GPT‑4 e Claude 3.5 Sonnet, especialmente em raciocínio complexo e tarefas de programação.
Inovações técnicas
1. Balanceamento de carga sem perda auxiliar
Abordagem inovadora que mantém o desempenho ideal sem as desvantagens dos mecanismos de perda auxiliar.
2. Predição multi‑token
Com recursos avançados de predição multi‑token, o DeepSeek V3 alcança:
- Geração mais rápida
- Melhor compreensão contextual
- Maior eficiência no processamento de tokens
Aplicações práticas
As implicações práticas são amplas:
- Janela de contexto estendida: 128.000 tokens para análise documental abrangente
- Velocidade de geração: até 90 tokens/segundo
- Eficiência de recursos: custos de implantação significativamente reduzidos
O futuro do desenvolvimento em IA
Mais do que um lançamento, o DeepSeek V3 marca uma mudança fundamental na forma de encarar o desenvolvimento de IA. Ao demonstrar que é possível obter desempenho de elite com muito menos recursos, abre caminho para:
- Entrada de organizações menores no setor
- Práticas de desenvolvimento mais sustentáveis
- Inovação acelerada em arquitetura de modelos
Conclusão
O DeepSeek V3 é um testemunho do poder do pensamento inovador no desenvolvimento de IA. Ao desafiar abordagens convencionais de arquitetura e treinamento, estabelece novos padrões de eficiência mantendo desempenho de alto nível.
"O DeepSeek V3 não apenas expande os limites do possível em IA – ele os redefine. Sua abordagem revolucionária de eficiência e desempenho estabelece um novo padrão para todo o setor."