
DeepSeek V3 — Mendefinisikan ulang standar efisiensi AI
January 13, 2025
DeepSeek V3: terobosan besar dalam efisiensi AI
Dalam kemajuan penting bagi komunitas AI, DeepSeek V3 hadir sebagai model revolusioner yang menantang pemahaman tradisional tentang efisiensi dan biaya pelatihan. Analisis komprehensif ini membahas bagaimana DeepSeek V3 mencapai kinerja mutakhir sambil memangkas kebutuhan sumber daya secara drastis.
Inovasi arsitektur: kekuatan MoE
Inti dari DeepSeek V3 adalah arsitektur Mixture‑of‑Experts (MoE) yang canggih, yang secara fundamental mengubah cara kerja model bahasa berskala besar. Meskipun memiliki 671 miliar parameter, model ini secara cerdas hanya mengaktifkan 37 miliar per inferensi—sebuah perubahan paradigma dalam efisiensi.
Komponen arsitektur kunci:
-
Aktivasi parameter cerdas
- Keterlibatan pakar secara selektif sesuai kebutuhan tugas
- Pengurangan signifikan beban komputasi
- Kualitas kinerja terjaga meski parameter aktif lebih sedikit
-
Multi‑head Latent Attention (MLA)
- Peningkatan pemrosesan konteks
- Jejak memori lebih kecil saat inferensi
- Mekanisme ekstraksi informasi yang dioptimalkan
Menembus hambatan biaya
Implikasi finansial dari inovasi DeepSeek V3 sangat mencolok:
- Biaya pelatihan: $5.6 juta
- Durasi pelatihan: 57 hari
- Jam GPU: 2,788 juta jam GPU H800
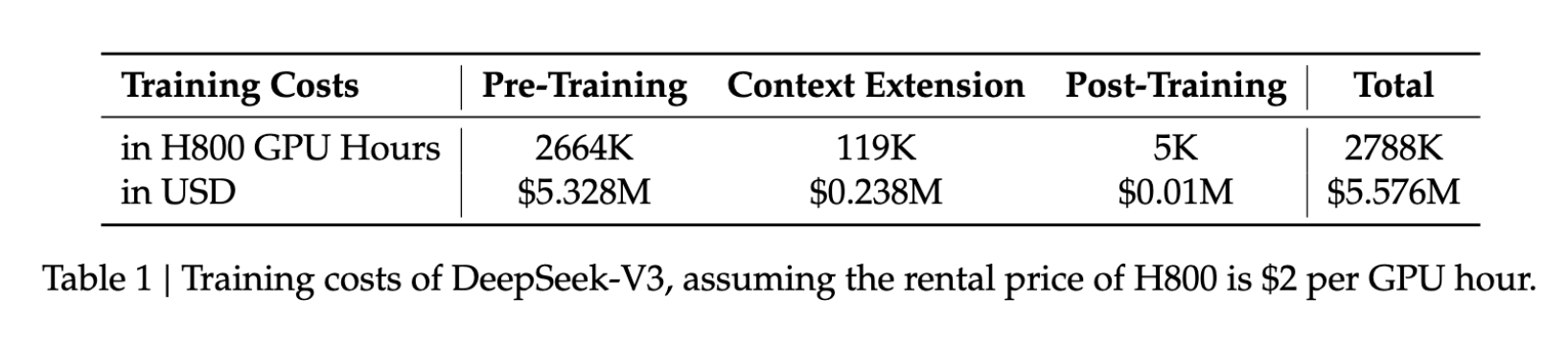
Dibandingkan model sekelasnya, angka ini hanyalah sebagian kecil dari sumber daya yang biasanya dibutuhkan, sehingga pengembangan AI tingkat lanjut menjadi lebih terjangkau bagi banyak organisasi.
Kinerja yang berbicara sendiri
Terlepas dari desain yang berfokus pada efisiensi, DeepSeek V3 menunjukkan kinerja luar biasa di benchmark kunci:
| Benchmark | Skor |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
Hasil ini menempatkan DeepSeek V3 pada jajaran teratas bersama GPT‑4 dan Claude 3.5 Sonnet, terutama pada penalaran kompleks dan tugas pemrograman.
Inovasi teknis
1. Penyeimbangan beban tanpa auxiliary loss
Pendekatan baru yang mempertahankan performa optimal tanpa kelemahan mekanisme auxiliary loss.
2. Prediksi multi‑token
Dengan kemampuan prediksi multi‑token tingkat lanjut, DeepSeek V3 mencapai:
- Kecepatan generasi yang lebih tinggi
- Pemahaman konteks yang lebih baik
- Efisiensi pemrosesan token yang lebih tinggi
Aplikasi praktis
Implikasi praktis yang luas:
- Jendela konteks yang diperluas: 128.000 token untuk analisis dokumen komprehensif
- Kecepatan generasi: hingga 90 token/detik
- Efisiensi sumber daya: biaya penerapan yang jauh lebih rendah
Masa depan pengembangan AI
DeepSeek V3 bukan sekadar rilis baru; ini menandai pergeseran paradigma dalam pengembangan AI. Dengan membuktikan bahwa performa tingkat atas dapat dicapai dengan sumber daya yang jauh lebih sedikit, model ini membuka jalan bagi:
- Masuknya organisasi skala kecil ke ranah AI
- Praktik pengembangan yang lebih berkelanjutan
- Inovasi arsitektur model yang lebih cepat
Kesimpulan
DeepSeek V3 adalah bukti kekuatan pemikiran inovatif dalam pengembangan AI. Dengan menantang pendekatan arsitektur dan pelatihan konvensional, ia menetapkan standar baru dalam efisiensi sambil mempertahankan performa kelas elite.
"DeepSeek V3 tidak sekadar mendorong batas kemungkinan dalam AI—ia mendefinisikannya ulang. Pendekatan revolusioner terhadap efisiensi dan performa menetapkan tolok ukur baru bagi seluruh industri."