
DeepSeek V3 – Neue Maßstäbe für Effizienz in der KI
January 13, 2025
DeepSeek V3: Ein bahnbrechender Durchbruch in der KI‑Effizienz
DeepSeek V3 hat sich als wegweisendes Modell erwiesen, das unser Verständnis von Effizienz und Wirtschaftlichkeit im KI‑Training grundlegend herausfordert. Diese umfassende Analyse zeigt, wie DeepSeek V3 State‑of‑the‑Art‑Leistung erreicht und gleichzeitig die Ressourcenanforderungen drastisch senkt.
Architektonische Innovation: Die Stärke von MoE
Im Kern nutzt DeepSeek V3 eine ausgefeilte Mixture‑of‑Experts (MoE)‑Architektur, die die Arbeitsweise großer Sprachmodelle grundlegend verändert. Obwohl das Modell 671 Milliarden Parameter umfasst, werden pro Inferenz intelligent nur 37 Milliarden aktiviert – ein Paradigmenwechsel in puncto Effizienz.
Wichtige Architekturbausteine:
-
Intelligente Parameteraktivierung
- Selektive Expert:innen‑Einbindung je nach Aufgabenanforderung
- Deutlich geringerer Rechenaufwand
- Hohe Qualität trotz weniger aktiver Parameter
-
Multi‑head Latent Attention (MLA)
- Verbessertes Kontextverständnis
- Geringerer Speicherbedarf während der Inferenz
- Optimierte Informationsgewinnung
Kostenbarrieren durchbrechen
Die finanziellen Auswirkungen der Innovationen von DeepSeek V3 sind beträchtlich:
- Trainingskosten: 5,6 Mio. US‑$
- Trainingsdauer: 57 Tage
- GPU‑Nutzung: 2,788 Mio. H800‑GPU‑Stunden
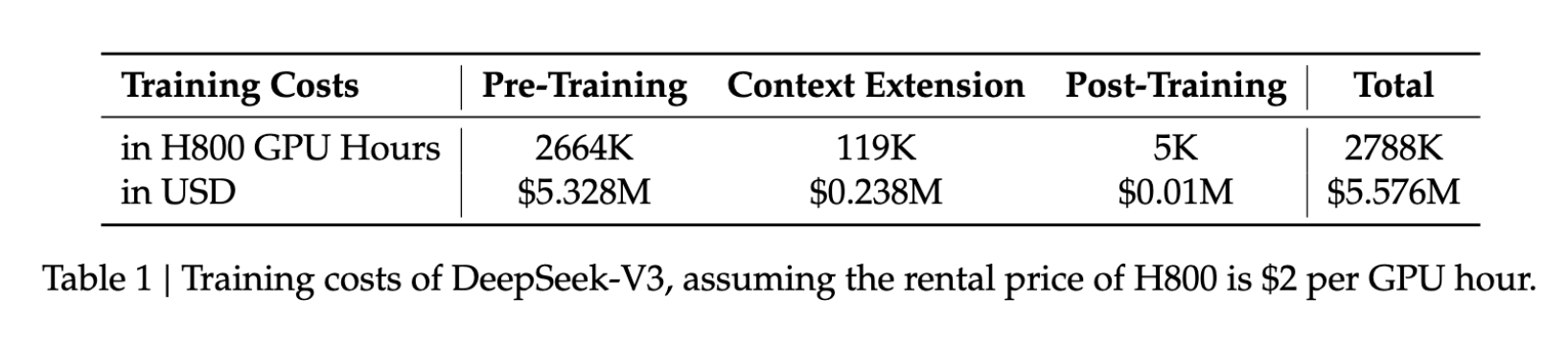
Diese Werte entsprechen nur einem Bruchteil der Ressourcen, die üblicherweise für vergleichbare Modelle benötigt werden – und machen fortgeschrittene KI‑Entwicklung breiter zugänglich.
Leistung, die überzeugt
Trotz des Effizienzfokus liefert DeepSeek V3 herausragende Ergebnisse auf zentralen Benchmarks:
| Benchmark | Wert |
|---|---|
| MMLU | 87,1 % |
| BBH | 87,5 % |
| DROP | 89,0 % |
| HumanEval | 65,2 % |
| MBPP | 75,4 % |
| GSM8K | 89,3 % |
Damit positioniert sich DeepSeek V3 auf Augenhöhe mit Branchenführern wie GPT‑4 und Claude 3.5 Sonnet – insbesondere bei komplexem Schlussfolgern und Coding‑Aufgaben.
Technische Innovationen
1. Lastenausgleich ohne Hilfsverlust
Neuer Ansatz für Lastverteilung, der optimale Performance ohne typische Nachteile von Auxiliary‑Loss‑Mechanismen ermöglicht.
2. Multi‑Token‑Vorhersage
Durch fortgeschrittene Multi‑Token‑Vorhersage erreicht DeepSeek V3:
- Schnellere Textgenerierung
- Besseres Kontextverständnis
- Effizientere Token‑Verarbeitung
Praktische Einsatzfelder
Die praktischen Auswirkungen sind weitreichend:
- Erweitertes Kontextfenster: 128.000 Token für umfassende Dokumentenanalyse
- Generationsgeschwindigkeit: bis zu 90 Token/Sekunde
- Ressourceneffizienz: Deutlich geringere Betriebskosten
Die Zukunft der KI‑Entwicklung
DeepSeek V3 ist mehr als ein weiterer Release; es markiert einen grundlegenden Wandel in der KI‑Entwicklung. Das Modell zeigt, dass Spitzenleistung mit deutlich weniger Ressourcen möglich ist – und ebnet den Weg für:
- Den Einstieg kleinerer Organisationen
- Nachhaltigere Entwicklungspraktiken
- Schnellere Innovationen in der Modellarchitektur
Fazit
DeepSeek V3 ist ein eindrucksvoller Beleg für die Kraft innovativen Denkens. Durch die Abkehr von konventionellen Ansätzen bei Architektur und Training setzt es neue Effizienzmaßstäbe – bei gleichbleibend exzellenter Performance.
„DeepSeek V3 verschiebt nicht nur die Grenzen des Möglichen – es definiert sie neu. Der revolutionäre Ansatz in Effizienz und Leistung setzt einen neuen Branchenstandard.“