DeepSeek v3 Capabilities
Explore the impressive capabilities of DeepSeek v3 across different domains - from complex reasoning to code generation
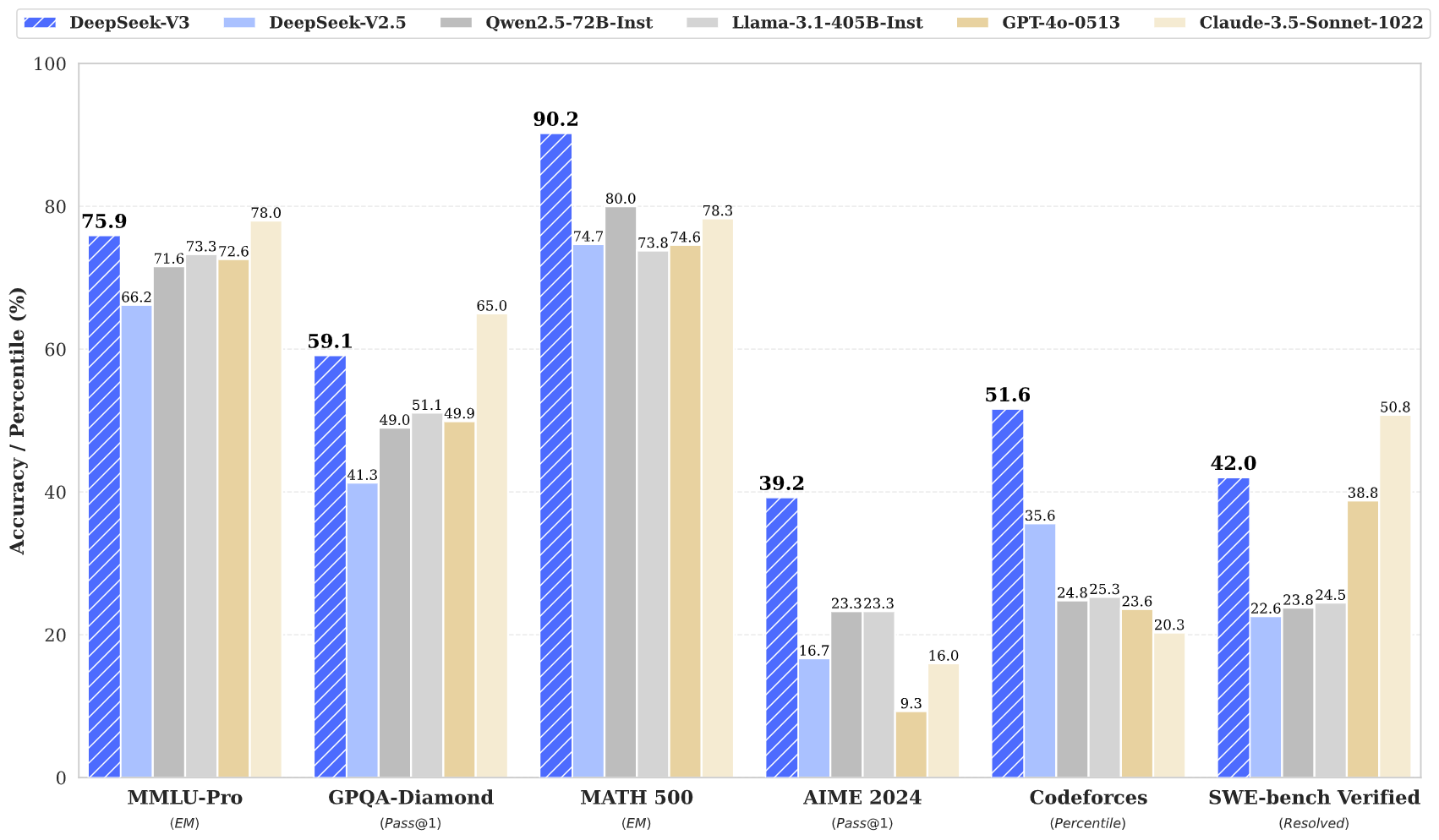

DeepSeek v3 represents a major breakthrough in AI language models, featuring 671B total parameters with 37B activated for each token. Built on innovative Mixture-of-Experts (MoE) architecture, DeepSeek v3 delivers state-of-the-art performance across various benchmarks while maintaining efficient inference.
Explore the impressive capabilities of DeepSeek v3 across different domains - from complex reasoning to code generation
Discover what makes DeepSeek v3 a leading choice in large language models
DeepSeek v3 utilizes an innovative Mixture-of-Experts architecture with 671B total parameters, activating 37B parameters for each token for optimal performance.
Pre-trained on 14.8 trillion high-quality tokens, DeepSeek v3 demonstrates comprehensive knowledge across various domains.
DeepSeek v3 achieves state-of-the-art results across multiple benchmarks, including mathematics, coding, and multilingual tasks.
Despite its large size, DeepSeek v3 maintains efficient inference capabilities through innovative architecture design.
With a 128K context window, DeepSeek v3 can process and understand extensive input sequences effectively.
DeepSeek v3 incorporates advanced Multi-Token Prediction for enhanced performance and inference acceleration.
Access the power of DeepSeek v3 in three simple steps
Select from various tasks including text generation, code completion, and mathematical reasoning. DeepSeek v3 excels across multiple domains.
Enter your prompt or question. DeepSeek v3's advanced architecture ensures high-quality responses with its 671B parameter model.
Experience DeepSeek v3's superior performance with responses that demonstrate advanced reasoning and understanding.
Discover how DeepSeek v3 is advancing the field of AI language models
Stay updated with the latest news and insights from the DeepSeek v3

DeepSeek V3.1 - A Comprehensive Analysis of the Latest Open-Source AI Model

DeepSeek-V3-0324 Update - Comprehensive Upgrades Across All Capabilities

DeepSeek V3 - Redefining AI Efficiency Standards
DeepSeek v3 represents the latest advancement in large language models, featuring a groundbreaking Mixture-of-Experts architecture with 671B total parameters. This innovative model demonstrates exceptional performance across various benchmarks, including mathematics, coding, and multilingual tasks.
Trained on 14.8 trillion diverse tokens and incorporating advanced techniques like Multi-Token Prediction, DeepSeek v3 sets new standards in AI language modeling. The model supports a 128K context window and delivers performance comparable to leading closed-source models while maintaining efficient inference capabilities.
DeepSeek v3 combines a massive 671B parameter MoE architecture with innovative features like Multi-Token Prediction and auxiliary-loss-free load balancing, delivering exceptional performance across various tasks.
DeepSeek v3 is available through our online demo platform and API services. You can also download the model weights for local deployment.
DeepSeek v3 demonstrates superior performance in mathematics, coding, reasoning, and multilingual tasks, consistently achieving top results in benchmark evaluations.
DeepSeek v3 supports various deployment options including NVIDIA GPUs, AMD GPUs, and Huawei Ascend NPUs, with multiple framework options for optimal performance.
Yes, DeepSeek v3 supports commercial use subject to the model license terms.
DeepSeek v3 outperforms other open-source models and achieves performance comparable to leading closed-source models across various benchmarks.
DeepSeek v3 can be deployed using multiple frameworks including SGLang, LMDeploy, TensorRT-LLM, vLLM, and supports both FP8 and BF16 inference modes.
DeepSeek v3 features a 128K context window, allowing it to process and understand extensive input sequences effectively for complex tasks and long-form content.
DeepSeek v3 was pre-trained on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages. The training process was remarkably stable with no irrecoverable loss spikes.
DeepSeek v3 utilizes FP8 mixed precision training and achieves efficient cross-node MoE training through algorithm-framework-hardware co-design, completing pre-training with only 2.788M H800 GPU hours.