Esplorare le innovazioni tecniche di DeepSeek V3
January 7, 2025
Esplorare le innovazioni tecniche di DeepSeek V3
DeepSeek V3 si è affermato come uno dei principali modelli di IA open source, combinando in modo eccezionale innovazione ed efficienza. Con 671 miliardi di parametri, ma solo 37 miliardi attivati per token, il modello è progettato per ottimizzare le prestazioni riducendo al minimo il consumo di risorse. In questo articolo analizziamo le principali innovazioni tecniche che distinguono DeepSeek V3 dai concorrenti.
Caratteristiche tecniche chiave
Architettura Mixture‑of‑Experts (MoE)
Al centro di DeepSeek V3 c’è l’architettura Mixture‑of‑Experts (MoE). Questo design sofisticato consente al modello di sfruttare più reti più piccole e specializzate per compito, che lavorano in collaborazione. Quando arriva una richiesta, una rete di gating determina quali esperti attivare, assicurando che vengano coinvolti solo i componenti necessari. Questa attivazione selettiva migliora in modo significativo efficienza e prestazioni.
Multi‑head Latent Attention (MLA)
DeepSeek V3 utilizza Multi‑head Latent Attention (MLA) per migliorare la comprensione del contesto e l’estrazione delle informazioni. Questo approccio mantiene alte prestazioni e, grazie a tecniche di compressione a basso rango, riduce l’uso di memoria durante l’inferenza. Il modello può così gestire in modo efficiente richieste complesse senza compromettere l’accuratezza.
Bilanciamento del carico senza perdita ausiliaria
Tra le innovazioni più rilevanti di DeepSeek V3 vi è la strategia di bilanciamento del carico senza perdita ausiliaria. I metodi tradizionali possono influire negativamente sulle prestazioni del modello; questo approccio innovativo ne riduce gli effetti, favorendo processi di addestramento più stabili ed efficienti.
Obiettivo di predizione multi‑token
DeepSeek V3 introduce un obiettivo di addestramento di predizione multi‑token, che migliora la capacità di generare testo coerente e contestualmente rilevante. Il modello può prevedere più token contemporaneamente, aumentando così la velocità di generazione e l’efficienza complessiva.
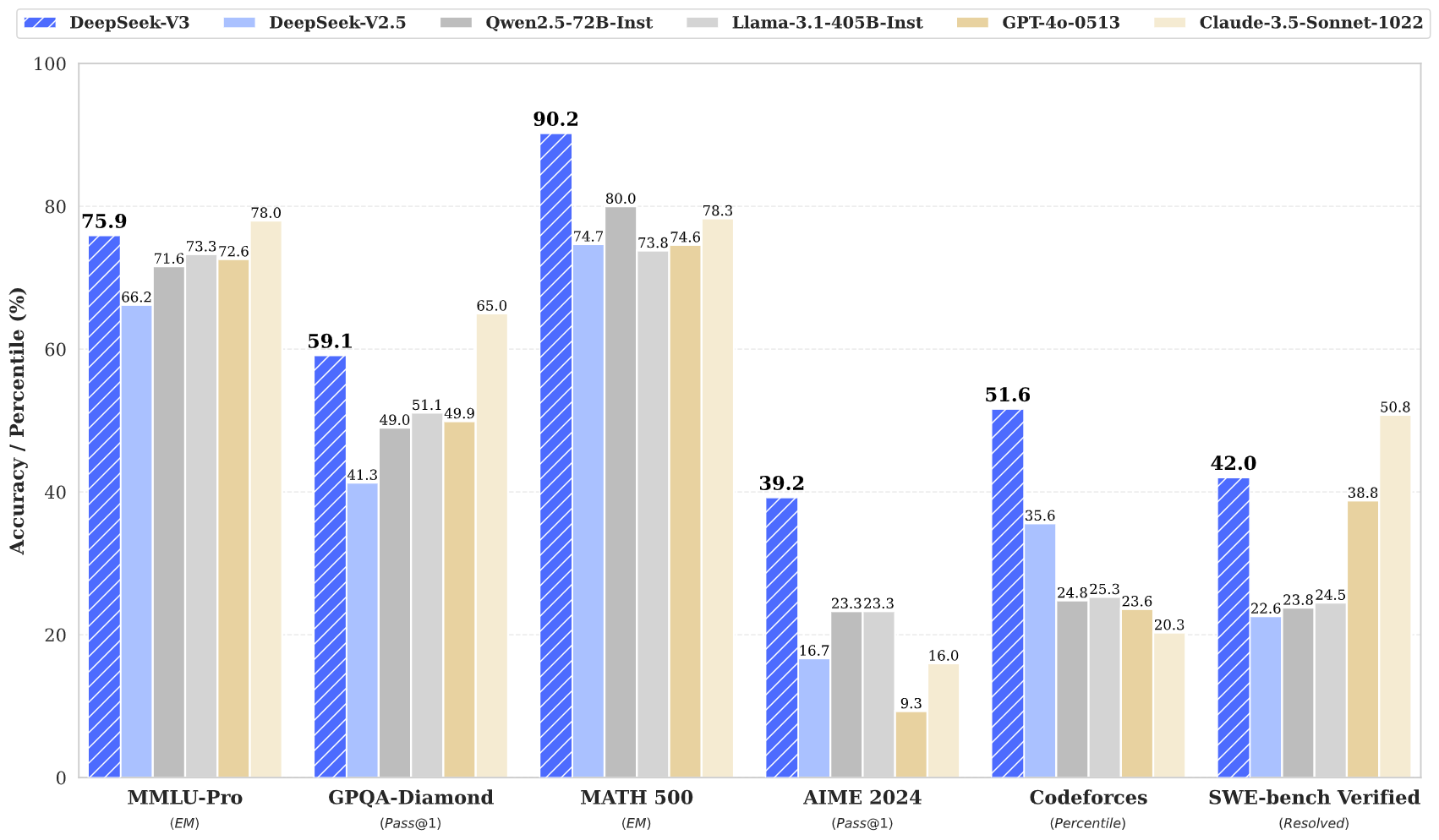
Metriche di prestazione
DeepSeek V3 ha dimostrato prestazioni eccezionali in diversi benchmark:
- MMLU: 87,1%
- BBH: 87,5%
- DROP: 89,0%
- HumanEval: 65,2%
- MBPP: 75,4%
- GSM8K: 89,3%
Questi risultati indicano che DeepSeek V3 non solo compete, ma spesso supera modelli closed‑source leader come GPT‑4 e Claude 3.5, in particolare in compiti di ragionamento complesso e programmazione.
Efficienza di addestramento
L’addestramento di DeepSeek V3 è stato realizzato con un’efficienza notevole:
- Costo totale di addestramento: Circa 5,6 milioni di $
- Durata dell’addestramento: 57 giorni
- Ore di GPU richieste: 2,788 milioni di ore GPU H800
Questo approccio economico evidenzia come un’architettura innovativa possa portare a risparmi significativi rispetto ai modelli tradizionali, che spesso richiedono risorse molto maggiori.
Finestra di contesto e velocità

DeepSeek V3 supporta un’impressionante finestra di contesto di 128.000 token, che consente di gestire efficacemente contenuti lunghi e compiti complessi. Inoltre, raggiunge una velocità di generazione fino a 90 token al secondo, rendendolo uno dei modelli più rapidi oggi disponibili.
Conclusione
In sintesi, DeepSeek V3 rappresenta un progresso rivoluzionario nell’IA open source. Le sue architetture innovative — MoE e MLA — unite a strategie di addestramento efficienti e a metriche di prestazione eccellenti, lo rendono un forte concorrente. Con la crescente domanda di soluzioni di IA potenti e accessibili, DeepSeek V3 è posizionato per guidare la democratizzazione della tecnologia IA.
DeepSeek V3 rappresenta una pietra miliare nello sviluppo dell’IA open source, combinando un’architettura all’avanguardia con un’efficienza notevole. Le sue metriche di prestazione e le sue innovazioni dimostrano che è possibile sviluppare modelli di alta qualità a una frazione dei costi tradizionali, rendendo la tecnologia IA avanzata più accessibile all’intera comunità.