Explorer les innovations techniques de DeepSeek V3
January 7, 2025
Explorer les innovations techniques de DeepSeek V3
DeepSeek V3 s’est imposé comme un acteur de premier plan parmi les modèles d’IA open source, alliant de façon remarquable innovation et efficacité. Avec 671 milliards de paramètres et seulement 37 milliards activés par token, ce modèle est conçu pour optimiser les performances tout en minimisant la consommation de ressources. Dans cet article, nous examinerons en détail les innovations techniques clés qui distinguent DeepSeek V3 de ses concurrents.
Caractéristiques techniques clés
Architecture Mixture-of-Experts (MoE)
Au cœur de DeepSeek V3 se trouve l’architecture Mixture-of-Experts (MoE). Cette conception sophistiquée permet d’exploiter plusieurs réseaux plus petits, spécialisés par tâche, qui travaillent en collaboration. Lorsqu’une requête est reçue, un réseau de routage (gating) détermine quels experts activer, garantissant que seuls les composants nécessaires sont engagés. Cette activation sélective améliore significativement l’efficacité et les performances.
Multi-head Latent Attention (MLA)
DeepSeek V3 utilise Multi-head Latent Attention (MLA) pour améliorer la compréhension du contexte et l’extraction d’information. Cette approche maintient des performances élevées tout en réduisant l’usage mémoire lors de l’inférence grâce à des techniques de compression de rang faible. Le modèle peut ainsi traiter efficacement des requêtes complexes sans compromettre la précision.
Répartition de charge sans perte auxiliaire
Parmi les innovations marquantes de DeepSeek V3 figure sa stratégie de répartition de charge sans perte auxiliaire. Les méthodes traditionnelles de répartition peuvent dégrader les performances ; cette approche novatrice en minimise les effets indésirables, rendant l’entraînement plus stable et efficace.
Objectif de prédiction multi-token
DeepSeek V3 introduit un objectif d’entraînement de prédiction multi-token, renforçant sa capacité à générer un texte cohérent et contextuellement pertinent. Cette fonctionnalité lui permet de prédire plusieurs tokens simultanément, améliorant la vitesse de génération et l’efficacité globale.
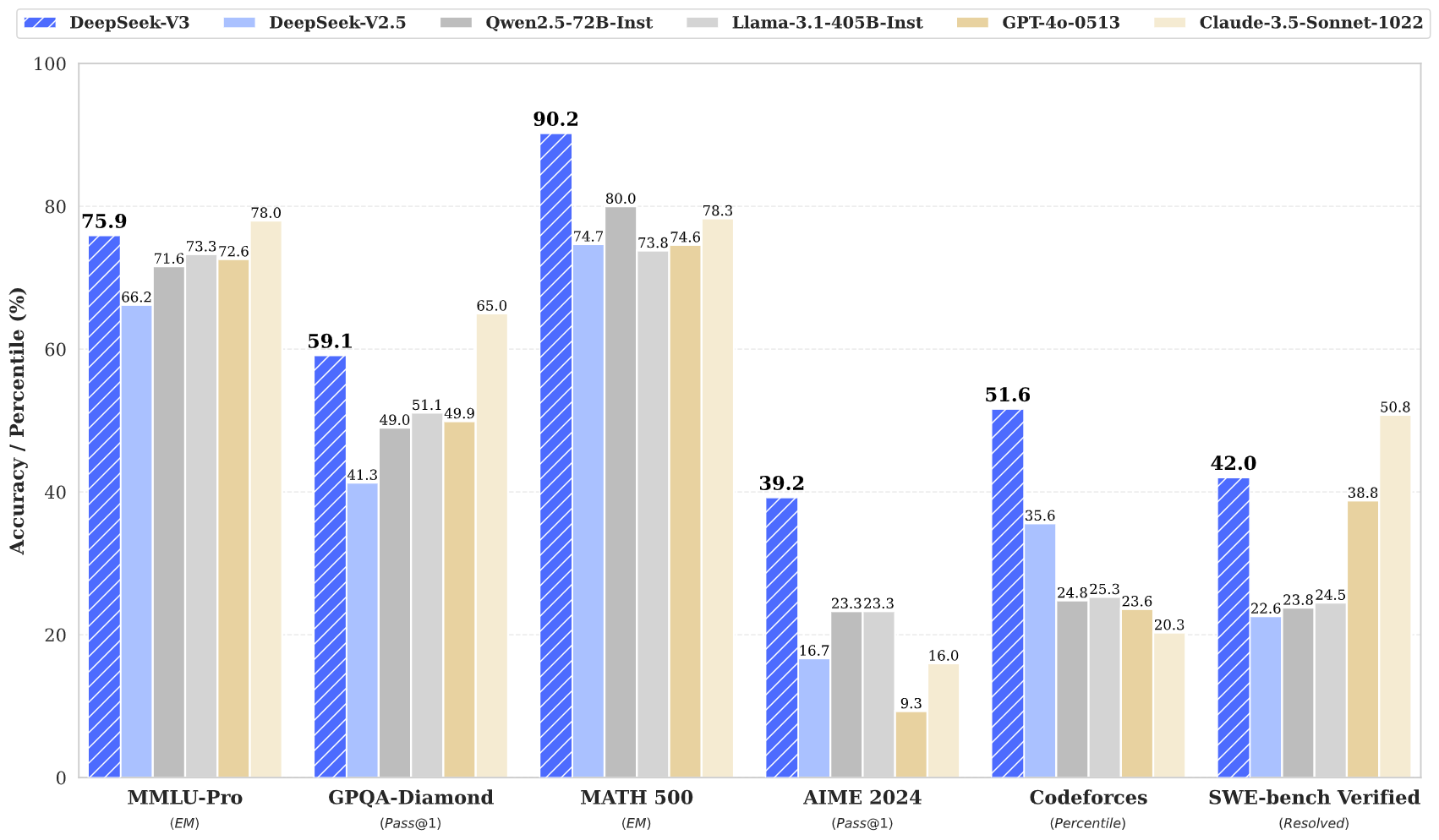
Mesures de performance
DeepSeek V3 affiche des performances remarquables sur divers benchmarks :
- MMLU : 87,1 %
- BBH : 87,5 %
- DROP : 89,0 %
- HumanEval : 65,2 %
- MBPP : 75,4 %
- GSM8K : 89,3 %
Ces résultats montrent que DeepSeek V3 rivalise, et dépasse souvent, des modèles propriétaires de pointe tels que GPT-4 et Claude 3.5, en particulier pour le raisonnement complexe et les tâches de programmation.
Efficacité d’entraînement
L’entraînement de DeepSeek V3 a été réalisé avec une efficacité remarquable :
- Coût total d’entraînement : Environ 5,6 M$
- Durée d’entraînement : 57 jours
- Heures GPU nécessaires : 2,788 millions d’heures GPU H800
Cette approche économique illustre comment une architecture innovante peut générer des économies substantielles par rapport aux modèles traditionnels, souvent bien plus gourmands en ressources.
Fenêtre de contexte et vitesse

DeepSeek V3 prend en charge une fenêtre de contexte de 128 000 tokens, lui permettant de gérer efficacement des contenus longs et des tâches complexes. Il propose en outre une vitesse de génération allant jusqu’à 90 tokens par seconde, ce qui en fait l’un des modèles les plus rapides disponibles aujourd’hui.
Conclusion
En somme, DeepSeek V3 s’impose comme une avancée révolutionnaire dans l’IA open source. Ses architectures innovantes — MoE et MLA — combinées à des stratégies d’entraînement efficaces et à d’excellentes performances, en font un concurrent de premier plan. À mesure que la demande pour des solutions d’IA puissantes et accessibles augmente, DeepSeek V3 est idéalement positionné pour promouvoir la démocratisation de la technologie IA.
DeepSeek V3 représente une étape majeure dans le développement de l’IA open source, alliant architecture de pointe et efficacité remarquable. Ses performances et ses innovations démontrent que des modèles de haute qualité peuvent être développés à une fraction du coût traditionnel, rendant l’IA avancée plus accessible à la communauté.