Technische Innovationen von DeepSeek V3 entdecken
January 7, 2025
Technische Innovationen von DeepSeek V3 entdecken
DeepSeek V3 hat sich als bedeutender Akteur unter den Open-Source-KI‑Modellen etabliert und überzeugt durch eine beeindruckende Kombination aus Innovation und Effizienz. Mit 671 Milliarden Parametern, von denen pro Token nur 37 Milliarden aktiviert werden, ist dieses Modell darauf ausgelegt, die Leistung zu maximieren und gleichzeitig den Ressourcenverbrauch zu minimieren. In diesem Beitrag beleuchten wir die wichtigsten technischen Neuerungen, die DeepSeek V3 von der Konkurrenz abheben.
Zentrale technische Merkmale
Mixture‑of‑Experts (MoE)‑Architektur
Im Kern von DeepSeek V3 steht die Mixture‑of‑Experts (MoE)‑Architektur. Dieses ausgefeilte Design ermöglicht es dem Modell, mehrere kleinere, auf bestimmte Aufgaben spezialisierte Netze kollaborativ zu nutzen. Bei einer Anfrage entscheidet ein Gating‑Netz, welche Experten aktiviert werden, sodass nur die für die Aufgabe notwendigen Komponenten eingesetzt werden. Diese selektive Aktivierung steigert Effizienz und Leistung deutlich.
Multi‑head Latent Attention (MLA)
DeepSeek V3 verwendet Multi‑head Latent Attention (MLA), um Kontextverständnis und Informationsgewinnung zu verbessern. Dieser Ansatz erhält nicht nur eine hohe Performance aufrecht, sondern reduziert dank Low‑Rank‑Kompression auch den Speicherbedarf während der Inferenz. Dadurch kann DeepSeek V3 komplexe Anfragen effizient und präzise verarbeiten.
Hilfsverlustfreies Lastenausgleichsverfahren
Zu den herausragenden Innovationen von DeepSeek V3 zählt die Strategie des hilfsverlustfreien Lastenausgleichs. Herkömmliche Verfahren können die Modellleistung beeinträchtigen; dieser neuartige Ansatz minimiert solche Effekte und sorgt für ein stabileres und effizienteres Training.
Multi‑Token‑Vorhersageziel
DeepSeek V3 führt ein Trainingsziel der Multi‑Token‑Vorhersage ein, das die Fähigkeit zur kohärenten und kontextbezogenen Textgenerierung verbessert. Das Modell kann mehrere Token gleichzeitig vorhersagen, was die Generationsgeschwindigkeit und die Gesamteffizienz erhöht.
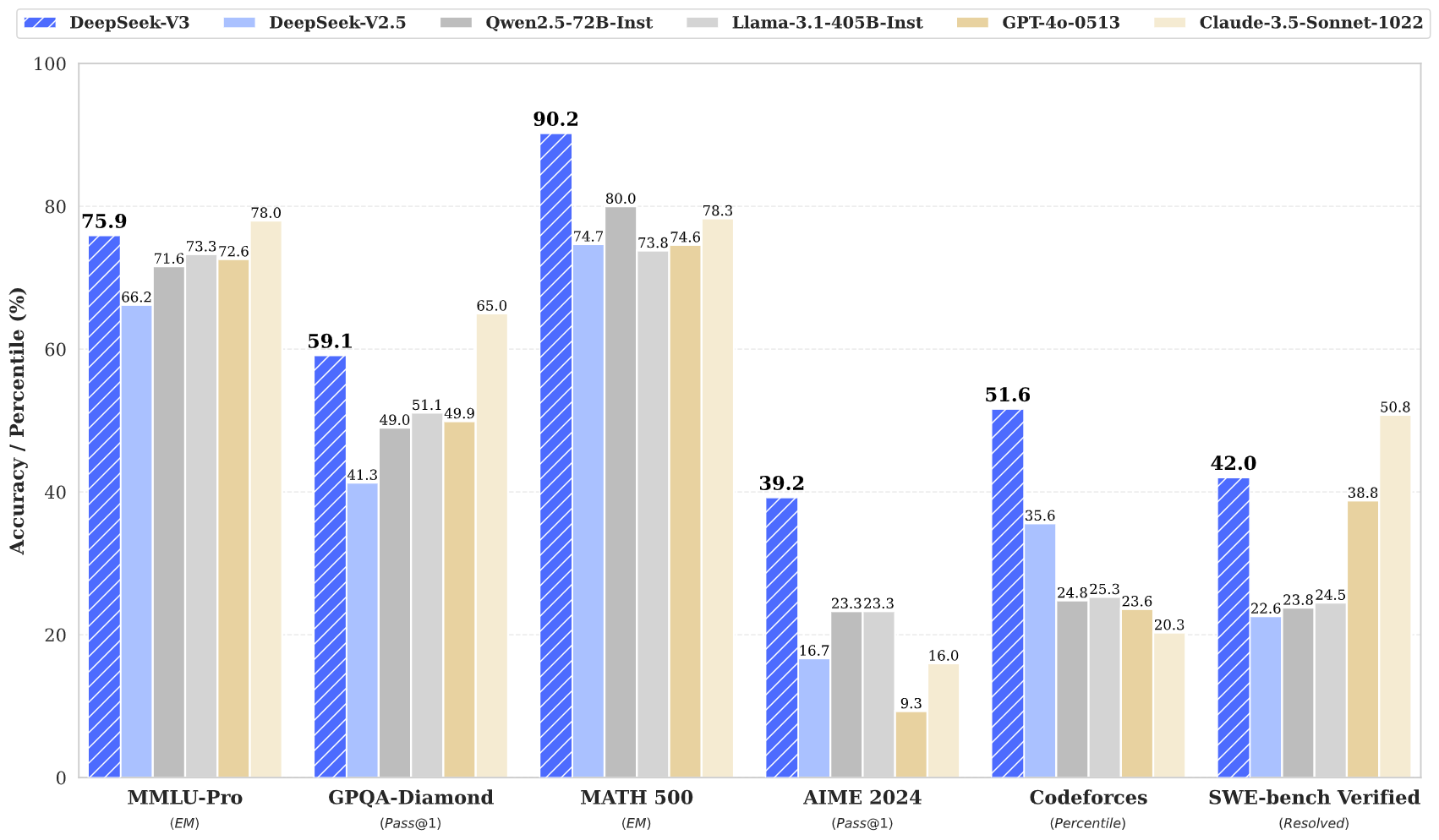
Leistungskennzahlen
DeepSeek V3 zeigt über verschiedene Benchmarks hinweg außergewöhnliche Ergebnisse:
- MMLU: 87,1 %
- BBH: 87,5 %
- DROP: 89,0 %
- HumanEval: 65,2 %
- MBPP: 75,4 %
- GSM8K: 89,3 %
Diese Werte belegen, dass DeepSeek V3 nicht nur mit führenden Closed‑Source‑Modellen wie GPT‑4 und Claude 3.5 konkurriert, sondern sie oftmals übertrifft – insbesondere bei komplexem Schlussfolgern und Programmieraufgaben.
Trainingseffizienz
Das Training von DeepSeek V3 wurde mit bemerkenswerter Effizienz erreicht:
- Gesamte Trainingskosten: ca. 5,6 Mio. US‑$
- Trainingsdauer: 57 Tage
- Erforderliche GPU‑Stunden: 2,788 Mio. H800‑GPU‑Stunden
Dieser kosteneffiziente Ansatz zeigt, wie innovative Architekturen zu erheblichen Einsparungen gegenüber traditionellen Modellen führen können, die häufig deutlich mehr Ressourcen benötigen.
Kontextfenster und Geschwindigkeit

DeepSeek V3 unterstützt ein beeindruckendes Kontextfenster von 128.000 Token und kann damit lange Inhalte und komplexe Aufgaben effektiv verarbeiten. Zudem erreicht das Modell eine Generationsgeschwindigkeit von bis zu 90 Token pro Sekunde und zählt damit zu den schnellsten derzeit verfügbaren Modellen.
Fazit
Zusammenfassend ist DeepSeek V3 ein bahnbrechender Fortschritt in der Open‑Source‑KI. Seine innovativen Architekturen – MoE und MLA – kombiniert mit effizienten Trainingsstrategien und starken Leistungswerten machen es zu einem starken Wettbewerber. Mit der wachsenden Nachfrage nach leistungsfähigen und zugänglichen KI‑Lösungen ist DeepSeek V3 hervorragend positioniert, um die Demokratisierung von KI‑Technologie voranzutreiben.
DeepSeek V3 stellt einen bedeutenden Meilenstein in der Open‑Source‑KI‑Entwicklung dar: modernste Architektur gepaart mit bemerkenswerter Effizienz. Die Leistungskennzahlen und Innovationen zeigen, dass hochwertige KI‑Modelle zu einem Bruchteil der traditionellen Kosten entwickelt werden können – und damit einer breiten Gemeinschaft zugänglich werden.