探索 DeepSeek V3 的技术创新
January 7, 2025
探索 DeepSeek V3 的技术创新
DeepSeek V3 在开源 AI 模型领域脱颖而出,兼具创新与高效。其拥有高达 6710 亿参数,但每个 token 仅激活 370 亿参数,在保证性能的同时显著降低资源消耗。本文将介绍使 DeepSeek V3 与众不同的关键技术创新。
关键技术特性
Mixture‑of‑Experts(MoE)架构
DeepSeek V3 的核心是 Mixture‑of‑Experts(MoE) 架构。该架构允许模型协同调用多个更小、针对特定任务的子网络。当接收查询时,gating 网络会决定需要激活的专家,仅启用必要组件,从而显著提升效率与性能。
Multi‑head Latent Attention(MLA)
DeepSeek V3 采用 Multi‑head Latent Attention(MLA),强化上下文理解与信息提取。该方法在保持高性能的同时,通过低秩压缩降低推理阶段的内存占用,使模型能高效处理复杂查询且不牺牲准确度。
无辅助损失的负载均衡
DeepSeek V3 的一项亮点是 无辅助损失(auxiliary‑loss‑free)的负载均衡策略。传统负载均衡方法可能损害模型表现;该创新做法有效减轻负面影响,使训练更稳定、更高效。
多 Token 预测训练目标
DeepSeek V3 引入 多 Token 预测 的训练目标,增强其生成连贯且符合语境文本的能力。模型可同时预测多个 token,从而提升生成速度与整体效率。
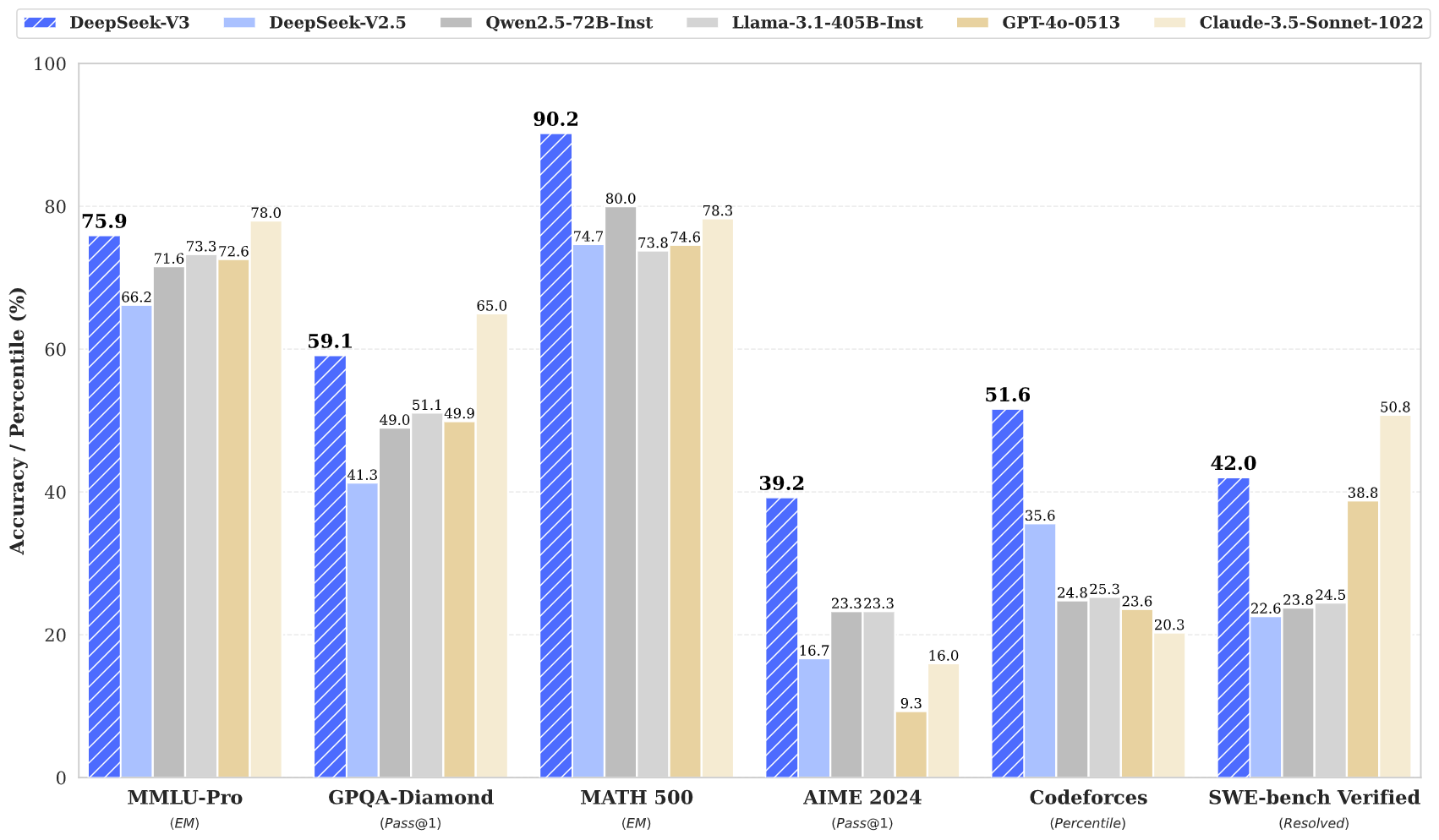
性能指标
DeepSeek V3 在多项基准测试中表现出色:
- MMLU:87.1%
- BBH:87.5%
- DROP:89.0%
- HumanEval:65.2%
- MBPP:75.4%
- GSM8K:89.3%
这些数据表明,DeepSeek V3 不仅能与 GPT‑4、Claude 3.5 等闭源顶尖模型竞争,甚至在复杂推理与编程任务中常有超越。
训练效率
DeepSeek V3 的训练以极高效率完成:
- 总训练成本:约 560 万美元
- 训练时长:57 天
- GPU 小时数:278.8 万 H800 GPU 小时
这一高性价比策略显示出创新架构相较传统模型可带来可观的资源节省,后者往往需要更高资源投入。
上下文窗口与速度

DeepSeek V3 支持 128,000 token 的超长上下文窗口,可高效处理长文本与复杂任务。同时,其生成速度可达 每秒 90 token,位居当前最快模型之列。
结语
总之,DeepSeek V3 是开源 AI 技术的重要跃升。其创新架构(MoE、MLA)、高效训练策略与卓越性能指标,使其在竞争激烈的领域中具备强劲实力。随着对强大且易用的 AI 解决方案需求持续增长,DeepSeek V3 有望引领 AI 技术的民主化。
DeepSeek V3 是开源 AI 发展的重要里程碑:前沿架构与卓越效率相结合。其性能指标与技术创新证明,高质量模型可在远低于传统成本的情况下实现,使先进 AI 技术更易为大众所用。