Исследуем технические инновации DeepSeek V3
January 7, 2025
Исследуем технические инновации DeepSeek V3
DeepSeek V3 зарекомендовал себя как мощная открытая модель ИИ, сочетающая инновации и эффективность. Обладая впечатляющими 671 миллиардами параметров, при этом активируя лишь 37 миллиардов на токен, модель оптимизирует производительность и сокращает потребление ресурсов. В этой статье мы рассмотрим ключевые технические новшества, отличающие DeepSeek V3 от конкурентов.
Ключевые технические особенности
Архитектура Mixture‑of‑Experts (MoE)
В основе DeepSeek V3 лежит архитектура Mixture‑of‑Experts (MoE). Этот сложный дизайн позволяет использовать несколько меньших, специализированных под задачи сетей, работающих совместно. При поступлении запроса управляющая (gating) сеть определяет, каких экспертов активировать, чтобы задействовать только необходимые компоненты. Такой выборочный подход существенно повышает эффективность и производительность.
Multi‑head Latent Attention (MLA)
DeepSeek V3 применяет Multi‑head Latent Attention (MLA) для улучшения понимания контекста и извлечения информации. Подход не только сохраняет высокую производительность, но и снижает потребление памяти на этапе вывода благодаря методам низкорангового сжатия, что позволяет эффективно обрабатывать сложные запросы без потери точности.
Балансировка нагрузки без вспомогательных потерь
Одним из заметных новшеств DeepSeek V3 является стратегия балансировки нагрузки без вспомогательных потерь. Традиционные методы могут отрицательно влиять на качество модели; новый подход минимизирует такие эффекты, делая обучение более стабильным и эффективным.
Многотокеновая предикция
DeepSeek V3 вводит обучающую цель многотокеновой предикции, усиливая способность модели генерировать связный и контекстно релевантный текст. Модель прогнозирует сразу несколько токенов, повышая скорость генерации и общую эффективность.
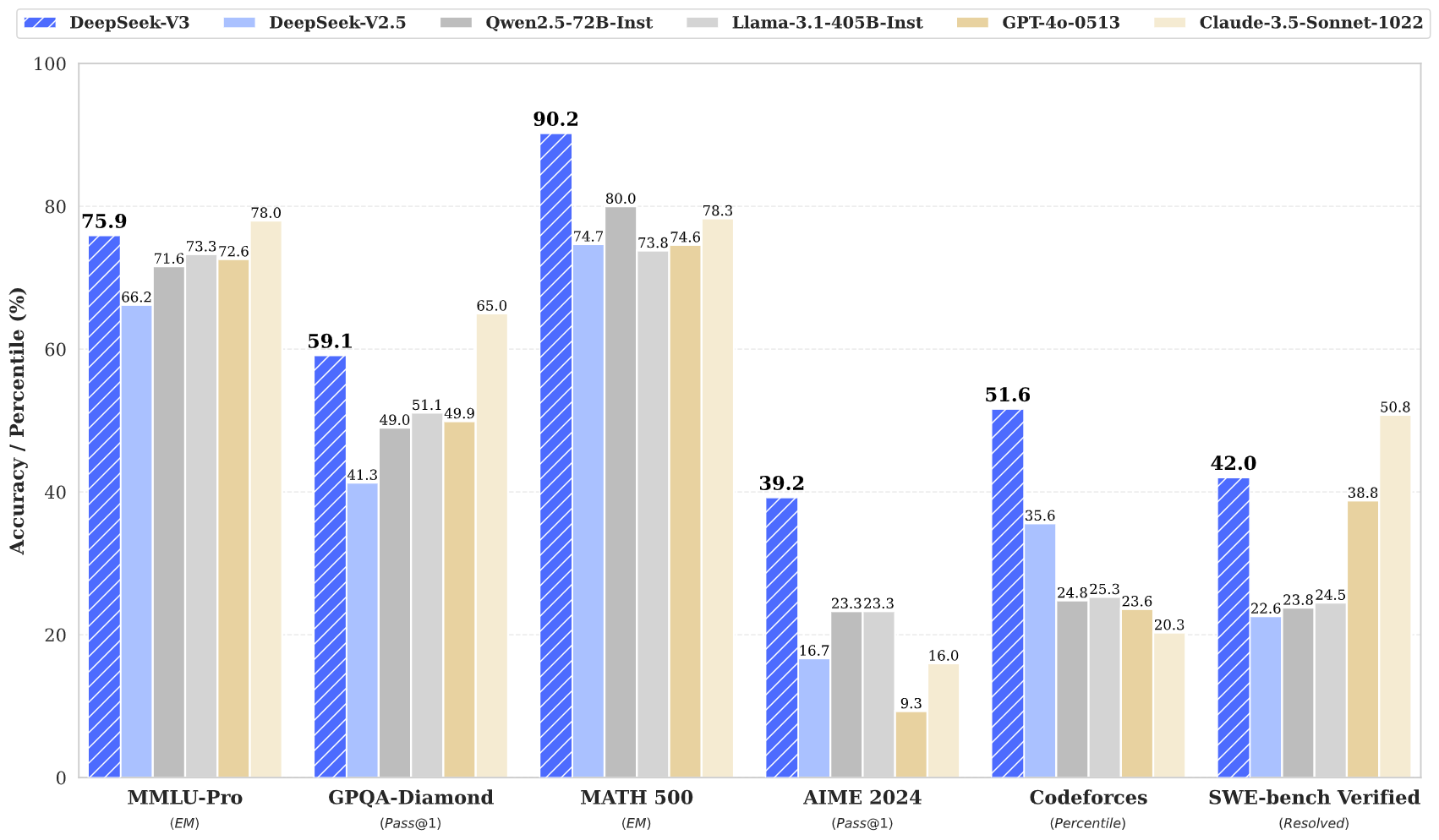
Показатели производительности
DeepSeek V3 демонстрирует выдающиеся результаты на различных бенчмарках:
- MMLU: 87,1%
- BBH: 87,5%
- DROP: 89,0%
- HumanEval: 65,2%
- MBPP: 75,4%
- GSM8K: 89,3%
Эти показатели показывают, что DeepSeek V3 не только сопоставим, но и нередко превосходит лидирующие закрытые модели, такие как GPT‑4 и Claude 3.5, особенно в задачах сложного рассуждения и программирования.
Эффективность обучения
Обучение DeepSeek V3 было выполнено с поразительной эффективностью:
- Итоговая стоимость обучения: около 5,6 млн долларов
- Длительность обучения: 57 дней
- Часы работы GPU: 2,788 млн часов на H800
Такой экономичный подход наглядно демонстрирует, что инновационная архитектура способна обеспечить значительную экономию по сравнению с традиционными моделями, которые обычно требуют намного больше ресурсов.
Контекстное окно и скорость

DeepSeek V3 поддерживает впечатляющее контекстное окно на 128 000 токенов, что позволяет эффективно работать с длинными текстами и решать сложные задачи. Кроме того, модель достигает скорости генерации до 90 токенов в секунду, являясь одной из самых быстрых на сегодняшний день.
Заключение
В целом, DeepSeek V3 — революционный шаг в развитии открытых технологий ИИ. Инновационные архитектуры — MoE и MLA — в сочетании с эффективными стратегиями обучения и высокими показателями производительности делают модель сильным конкурентом. С ростом спроса на мощные и доступные решения ИИ DeepSeek V3 занимает выгодную позицию для продвижения демократизации ИИ‑технологий.
DeepSeek V3 — важная веха в развитии open‑source ИИ: передовая архитектура и выдающаяся эффективность. Показатели и инновации доказывают, что качественные модели можно создавать за долю традиционных затрат, делая продвинутые ИИ‑технологии доступнее широкой аудитории.