DeepSeek V3 の技術的イノベーションを探る
January 7, 2025
DeepSeek V3 の技術的イノベーションを探る
DeepSeek V3 は、オープンソース AI モデルの分野において、革新性と効率性を兼ね備えた強力な存在として頭角を現しています。驚異的な 6,710 億パラメータ を持ちながら、トークンあたり実際に活性化されるのは 370 億パラメータ のみで、リソース消費を抑えつつ高いパフォーマンスを実現しています。本記事では、DeepSeek V3 を競合と一線を画す存在にしている主要な技術的革新に焦点を当てます。
主要な技術的特徴
Mixture‑of‑Experts (MoE) アーキテクチャ
DeepSeek V3 の中核には Mixture‑of‑Experts (MoE) アーキテクチャがあります。これは、タスク特化型の複数の小規模ネットワークを協調的に活用する高度な設計です。クエリ受信時にはゲーティングネットワークがどのエキスパートを活性化するかを判断し、必要なコンポーネントのみを動作させます。この選択的活性化により、効率性と性能が大幅に向上します。
Multi‑head Latent Attention (MLA)
DeepSeek V3 は Multi‑head Latent Attention (MLA) を採用し、文脈理解と情報抽出を強化します。この手法は高い性能を維持しつつ、低ランク圧縮により推論時のメモリ使用量を削減します。その結果、精度を保ちつつ複雑なクエリを効率的に処理できます。
補助損失を用いない負荷分散
DeepSeek V3 の注目すべき革新点の一つが、補助損失に依存しない負荷分散戦略です。従来の手法はモデル性能に悪影響を及ぼす場合がありますが、この新しいアプローチはその影響を最小化し、より安定かつ効率的な学習を実現します。
マルチトークン予測目的
DeepSeek V3 は マルチトークン予測 を学習目標として導入し、首尾一貫した文脈適合的なテキスト生成能力を高めています。複数トークンを同時に予測することで、生成速度と全体的な効率が向上します。
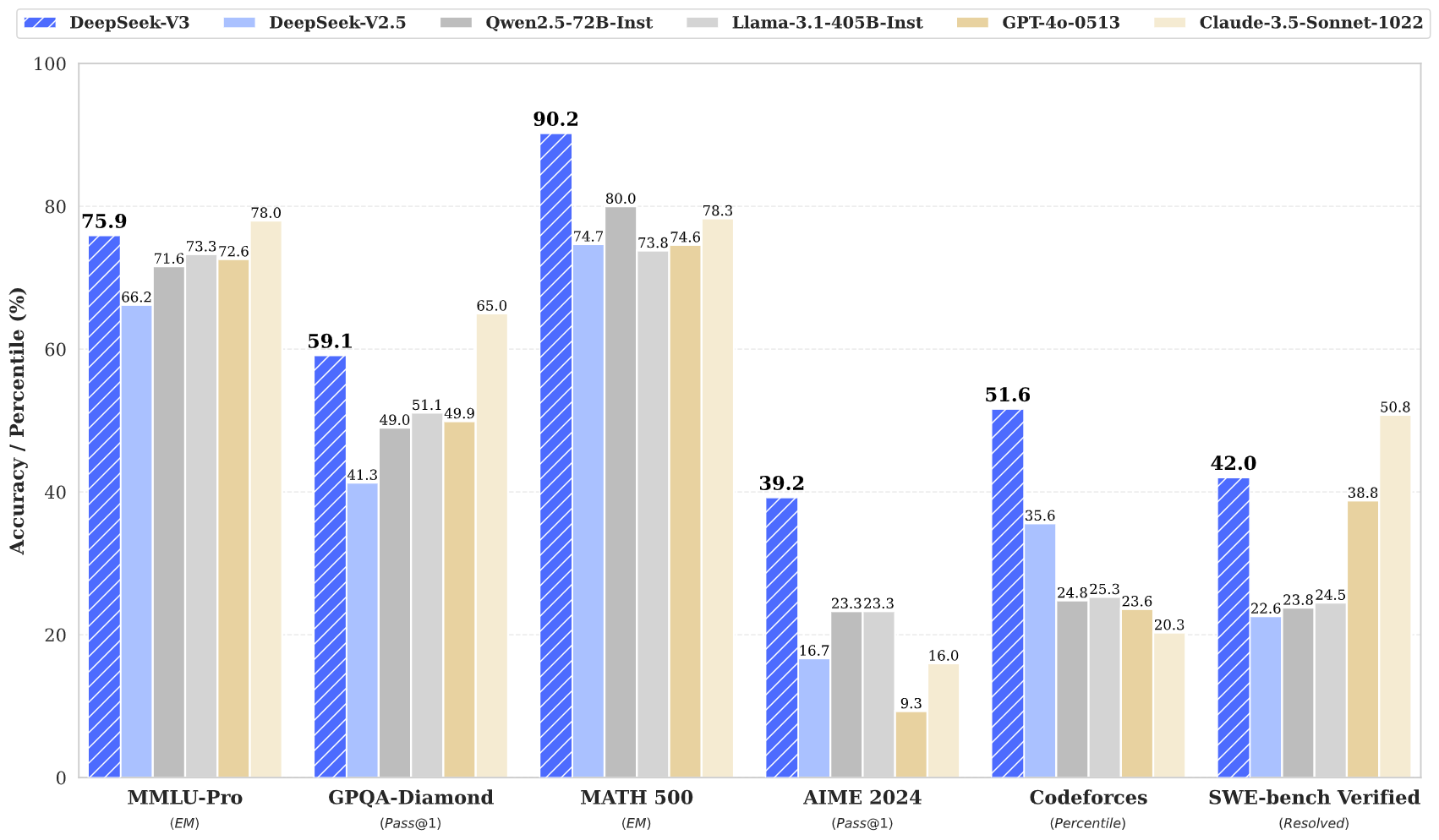
パフォーマンス指標
DeepSeek V3 は、さまざまなベンチマークで優れた成績を示しています。
- MMLU: 87.1%
- BBH: 87.5%
- DROP: 89.0%
- HumanEval: 65.2%
- MBPP: 75.4%
- GSM8K: 89.3%
これらの指標は、DeepSeek V3 が GPT‑4 や Claude 3.5 といったクローズドソースの最先端モデルに匹敵し、時には凌駕することを示しています。特に複雑な推論やコーディング課題で顕著です。
学習効率
DeepSeek V3 の学習は、驚くべき効率性で達成されました。
- 総学習コスト: 約 560 万米ドル
- 学習期間: 57 日
- 必要 GPU 時間: 278.8 万時間(H800)
このコスト効率の高いアプローチは、従来型モデルに比べ、革新的なアーキテクチャがいかに大幅なリソース節約につながるかを示しています。
コンテキストウィンドウと速度

DeepSeek V3 は 128,000 トークンのコンテキストウィンドウをサポートし、長文や複雑なタスクを効果的に処理します。さらに、最大 毎秒 90 トークン の生成速度を達成し、現行の中でも最速クラスのモデルです。
まとめ
総じて、DeepSeek V3 はオープンソース AI 技術の画期的な前進です。MoE と MLA という革新的なアーキテクチャ、効率的な学習戦略、そして優れたパフォーマンス指標により、競争の激しい分野で強力な存在感を放ちます。強力でアクセスしやすい AI ソリューションの需要が高まる中、DeepSeek V3 は AI テクノロジーの民主化を牽引するにふさわしいポジションにあります。
DeepSeek V3 は、最先端のアーキテクチャと際立つ効率性を兼ね備えた、オープンソース AI 開発の重要なマイルストーンです。性能指標と技術革新は、高品質な AI モデルが従来コストの一部で開発可能であることを示し、先進的な AI 技術をより広く利用可能にします。