Menjelajahi Inovasi Teknis DeepSeek V3
January 7, 2025
Menjelajahi Inovasi Teknis DeepSeek V3
DeepSeek V3 telah muncul sebagai pemain kuat di ranah model AI open‑source, menampilkan perpaduan mengesankan antara inovasi dan efisiensi. Dengan 671 miliar parameter, namun hanya 37 miliar yang diaktifkan per token, model ini dirancang untuk memaksimalkan performa sambil meminimalkan konsumsi sumber daya. Artikel ini membahas inovasi teknis utama yang membedakan DeepSeek V3 dari para pesaingnya.
Fitur Teknis Utama
Arsitektur Mixture‑of‑Experts (MoE)
Di inti DeepSeek V3 terdapat arsitektur Mixture‑of‑Experts (MoE). Desain canggih ini memungkinkan model memanfaatkan beberapa jaringan kecil khusus tugas yang bekerja secara kolaboratif. Saat menerima permintaan, jaringan gating menentukan pakar mana yang diaktifkan, sehingga hanya komponen yang diperlukan yang digunakan. Aktivasi selektif ini secara signifikan meningkatkan efisiensi dan performa.
Multi‑head Latent Attention (MLA)
DeepSeek V3 menggunakan Multi‑head Latent Attention (MLA) untuk meningkatkan pemahaman konteks dan ekstraksi informasi. Pendekatan ini tidak hanya mempertahankan kinerja tinggi, tetapi juga mengurangi penggunaan memori saat inferensi melalui teknik kompresi low‑rank. Hasilnya, model dapat memproses permintaan kompleks secara efisien tanpa mengorbankan akurasi.
Penyeimbangan beban tanpa kerugian bantu
Salah satu inovasi menonjol DeepSeek V3 adalah strategi penyeimbangan beban tanpa auxiliary loss. Metode tradisional sering berdampak negatif pada performa; pendekatan baru ini meminimalkan dampak tersebut, sehingga proses pelatihan menjadi lebih stabil dan efisien.
Tujuan prediksi multi‑token
DeepSeek V3 memperkenalkan tujuan pelatihan prediksi multi‑token, yang meningkatkan kemampuan menghasilkan teks yang koheren dan relevan secara kontekstual. Model dapat memprediksi beberapa token sekaligus, sehingga meningkatkan kecepatan generasi dan efisiensi keseluruhan.
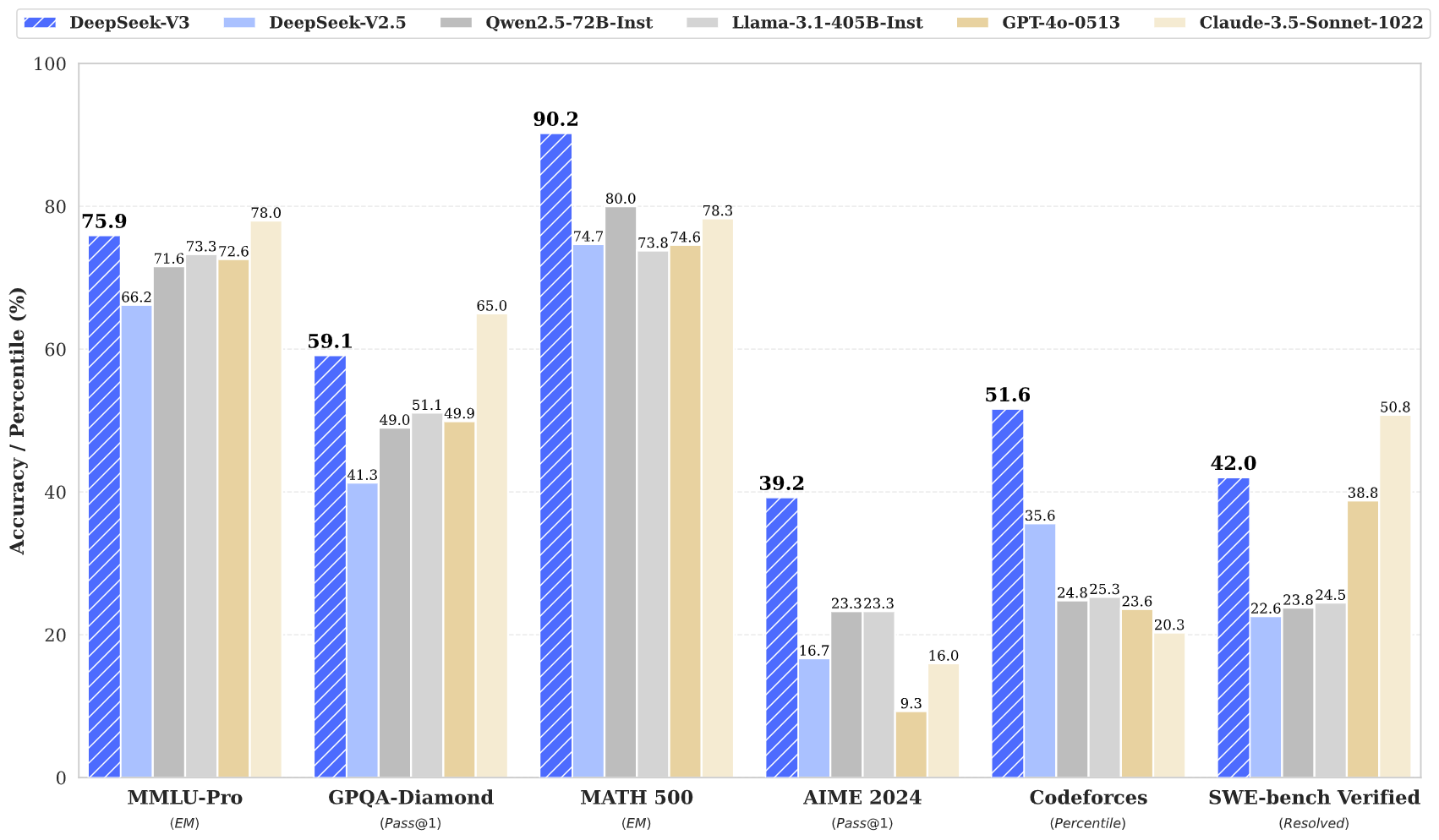
Metrik Performa
DeepSeek V3 menunjukkan performa luar biasa di berbagai benchmark:
- MMLU: 87,1%
- BBH: 87,5%
- DROP: 89,0%
- HumanEval: 65,2%
- MBPP: 75,4%
- GSM8K: 89,3%
Metrik ini menunjukkan bahwa DeepSeek V3 tidak hanya mampu bersaing, tetapi seringkali melampaui model closed‑source terkemuka seperti GPT‑4 dan Claude 3.5, khususnya pada tugas penalaran kompleks dan pemrograman.
Efisiensi Pelatihan
Pelatihan DeepSeek V3 dicapai dengan efisiensi luar biasa:
- Total biaya pelatihan: Sekitar US$ 5,6 juta
- Durasi pelatihan: 57 hari
- Jam GPU yang dibutuhkan: 2,788 juta jam GPU H800
Pendekatan hemat biaya ini menyoroti bagaimana arsitektur inovatif dapat menghasilkan penghematan signifikan dibandingkan model tradisional yang umumnya memerlukan sumber daya yang jauh lebih besar.
Jendela konteks dan kecepatan

DeepSeek V3 mendukung jendela konteks 128.000 token yang mengesankan, memungkinkan penanganan konten panjang dan tugas kompleks secara efektif. Selain itu, model ini mencapai kecepatan generasi hingga 90 token per detik, menjadikannya salah satu model tercepat yang tersedia saat ini.
Kesimpulan
Singkatnya, DeepSeek V3 merupakan lompatan besar dalam teknologi AI open‑source. Arsitektur inovatifnya — MoE dan MLA — dikombinasikan dengan strategi pelatihan yang efisien dan metrik performa yang mengesankan, menjadikannya pesaing kuat. Seiring meningkatnya permintaan akan solusi AI yang kuat dan mudah diakses, DeepSeek V3 berada pada posisi yang tepat untuk memimpin demokratisasi teknologi AI.
DeepSeek V3 menandai tonggak penting dalam pengembangan AI open‑source, menggabungkan arsitektur mutakhir dengan efisiensi yang luar biasa. Metrik dan inovasinya menunjukkan bahwa model berkualitas tinggi dapat dikembangkan dengan biaya jauh lebih rendah daripada pendekatan tradisional, sehingga membuat teknologi AI tingkat lanjut lebih mudah diakses oleh komunitas luas.