
DeepSeek V3 — AI दक्षता के नए मानक की पुनर्परिभाषा
January 13, 2025
DeepSeek V3: AI दक्षता में क्रांतिकारी突破
AI समुदाय के लिए एक महत्वपूर्ण प्रगति के रूप में, DeepSeek V3 एक क्रांतिकारी मॉडल के रूप में उभरा है, जो प्रशिक्षण दक्षता और लागत के पारंपरिक समझ को चुनौती देता है। यह व्यापक विश्लेषण बताता है कि DeepSeek V3 कैसे संसाधन आवश्यकताओं को नाटकीय रूप से घटाते हुए अत्याधुनिक प्रदर्शन प्राप्त करता है।
आर्किटेक्चर में नवाचार: MoE की शक्ति
DeepSeek V3 के केंद्र में परिष्कृत Mixture‑of‑Experts (MoE) आर्किटेक्चर है, जो बड़े भाषा मॉडलों के संचालन को मूल रूप से बदल देता है। भले ही इसमें 671 अरब पैरामीटर हों, यह अनुमान (inference) के समय बुद्धिमानी से केवल 37 अरब पैरामीटर सक्रिय करता है—दक्षता में एक नए प्रतिमान का संकेत।
प्रमुख आर्किटेक्चरल अवयव:
-
पैरामीटर का बुद्धिमान सक्रियण
- कार्य‑आवश्यकता के अनुसार विशेषज्ञों का चयनात्मक संलग्नीकरण
- संगणनात्मक ओवरहेड में भारी कमी
- कम सक्रिय पैरामीटर के बावजूद उच्च गुणवत्ता बनाए रखना
-
Multi‑head Latent Attention (MLA)
- संदर्भ प्रसंस्करण क्षमता में सुधार
- अनुमान के दौरान कम मेमोरी उपयोग
- सूचना निष्कर्षण तंत्र का अनुकूलन
लागत बाधाएँ तोड़ना
DeepSeek V3 के नवाचारों के वित्तीय निहितार्थ उल्लेखनीय हैं:
- प्रशिक्षण लागत: $5.6M
- प्रशिक्षण अवधि: 57 दिन
- GPU उपयोग: H800 पर 2.788M घंटे
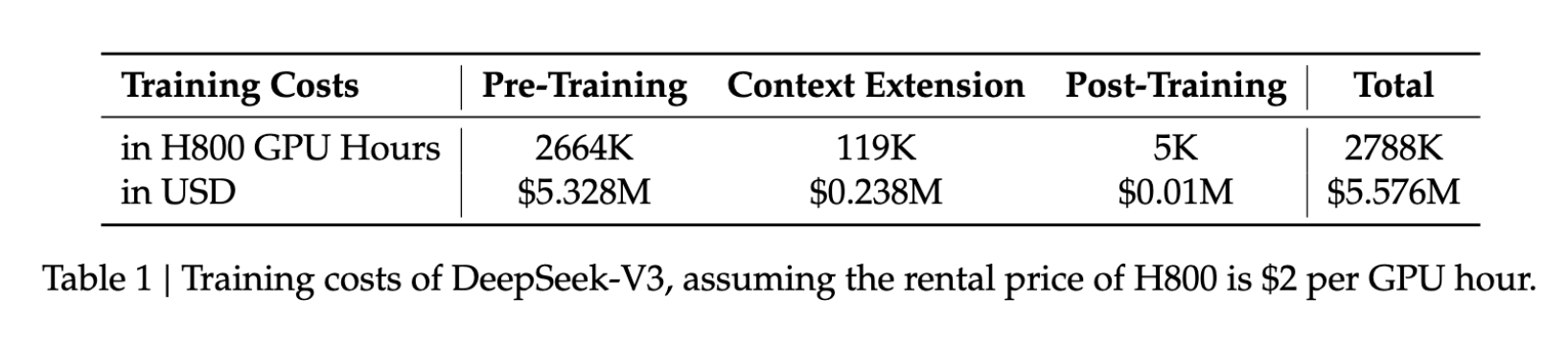
तुलनात्मक मॉडलों की तुलना में, ये आँकड़े आम तौर पर आवश्यक संसाधनों का केवल एक अंश हैं, जिससे उन्नत AI विकास अधिक संगठनों के लिए सुलभ होता है।
प्रदर्शन जो स्वयं बोलता है
दक्षता‑केंद्रित डिजाइन के बावजूद, DeepSeek V3 प्रमुख बेंचमार्क पर उत्कृष्ट प्रदर्शन दर्शाता है:
| बेंचमार्क | स्कोर |
|---|---|
| MMLU | 87.1% |
| BBH | 87.5% |
| DROP | 89.0% |
| HumanEval | 65.2% |
| MBPP | 75.4% |
| GSM8K | 89.3% |
ये परिणाम DeepSeek V3 को GPT‑4 और Claude 3.5 Sonnet जैसे उद्योग अग्रणियों के समकक्ष रखते हैं, विशेषकर जटिल तर्क‑वितर्क और कोडिंग कार्यों में।
तकनीकी नवाचार
1. सहायक‑हानि रहित लोड बैलेंसिंग
ऐसा नया दृष्टिकोण जो auxiliary loss तंत्र के दुष्प्रभावों से बचते हुए इष्टतम प्रदर्शन बनाए रखता है।
2. मल्टी‑टोकन प्रेडिक्शन
उन्नत मल्टी‑टोकन प्रेडिक्शन क्षमताओं के साथ, DeepSeek V3 प्राप्त करता है:
- तेज़ टेक्स्ट जनरेशन
- बेहतर संदर्भ समझ
- अधिक कुशल टोकन प्रोसेसिंग
व्यावहारिक अनुप्रयोग
प्रायोगिक प्रभाव व्यापक हैं:
- विस्तारित संदर्भ‑विंडो: 128,000 टोकन, समग्र डॉक्युमेंट विश्लेषण हेतु
- जनरेशन गति: अधिकतम 90 टोकन/सेकंड
- संसाधन दक्षता: परिनियोजन लागत में स्पष्ट कमी
AI विकास का भविष्य
DeepSeek V3 केवल एक और रिलीज़ नहीं; यह AI विकास दृष्टिकोण में मौलिक परिवर्तन का संकेत है। यह दर्शाता है कि कहीं कम संसाधनों के साथ भी शीर्ष‑स्तरीय प्रदर्शन संभव है, जिससे निम्न संभावनाएँ खुलती हैं:
- छोटे संगठनों का AI क्षेत्र में प्रवेश
- अधिक टिकाऊ विकास प्रथाएँ
- मॉडल आर्किटेक्चर में तेज़ नवाचार
निष्कर्ष
DeepSeek V3 AI विकास में नवाचारी सोच की शक्ति का प्रमाण है। पारंपरिक आर्किटेक्चर और प्रशिक्षण पद्धतियों को चुनौती देकर, यह उत्कृष्ट प्रदर्शन को बनाए रखते हुए दक्षता के नए मानक स्थापित करता है।
"DeepSeek V3 केवल AI की सीमाओं को आगे नहीं बढ़ाता—बल्कि उन्हें पुनर्परिभाषित करता है। दक्षता और प्रदर्शन के प्रति इसका क्रांतिकारी दृष्टिकोण पूरे उद्योग के लिए नया मानदंड तय करता है।"