DeepSeek V3 की तकनीकी नवाचारों की पड़ताल
January 7, 2025
DeepSeek V3 की तकनीकी नवाचारों की पड़ताल
DeepSeek V3 ने ओपन‑सोर्स AI मॉडलों के क्षेत्र में नवाचार और दक्षता का उत्कृष्ट संतुलन प्रदर्शित करते हुए एक सशक्त स्थान बनाया है। इसमें 671 अरब पैरामीटर हैं, परंतु प्रति टोकन केवल 37 अरब पैरामीटर सक्रिय होते हैं—जिससे संसाधन‑उपयोग कम रहते हुए उच्च प्रदर्शन संभव होता है। इस लेख में, हम वे प्रमुख तकनीकी नवाचार देखेंगे जो DeepSeek V3 को प्रतिस्पर्धियों से अलग बनाते हैं।
प्रमुख तकनीकी विशेषताएँ
Mixture‑of‑Experts (MoE) आर्किटेक्चर
DeepSeek V3 का केंद्र इसकी Mixture‑of‑Experts (MoE) आर्किटेक्चर है। यह उन्नत डिजाइन कार्य‑विशेष छोटे नेटवर्कों को सहयोगी रूप से उपयोग में लाता है। किसी क्वेरी पर, गेटिंग नेटवर्क यह निर्धारित करता है कि किन विशेषज्ञों को सक्रिय किया जाए, जिससे हर कार्य के लिए केवल आवश्यक घटक ही सक्रिय हों। यह चयनात्मक सक्रियण दक्षता और प्रदर्शन दोनों में महत्वपूर्ण वृद्धि करता है。
Multi‑head Latent Attention (MLA)
DeepSeek V3 Multi‑head Latent Attention (MLA) का उपयोग करता है जो संदर्भ‑समझ और सूचना‑निष्कर्षण को बेहतर बनाता है। यह तरीका उच्च प्रदर्शन बनाए रखते हुए लो‑रैंक कम्प्रेशन के माध्यम से अनुमान (inference) के दौरान मेमोरी‑खपत कम करता है। परिणामस्वरूप, मॉडल जटिल क्वेरियों को बिना शुद्धता घटाए प्रभावी रूप से संसाधित कर पाता है।
सहायक‑हानि रहित लोड बैलेंसिंग
DeepSeek V3 की उल्लेखनीय नवाचारों में से एक है सहायक‑हानि (auxiliary loss) रहित लोड बैलेंसिंग रणनीति। पारंपरिक तरीकों से मॉडल‑प्रदर्शन पर प्रतिकूल प्रभाव पड़ सकता है; यह नया दृष्टिकोण उन प्रभावों को न्यूनतम करता है, जिससे प्रशिक्षण अधिक स्थिर और कुशल बनता है।
मल्टी‑टोकन प्रेडिक्शन उद्देश्य
DeepSeek V3 मल्टी‑टोकन प्रेडिक्शन को प्रशिक्षण उद्देश्य के रूप में प्रस्तुत करता है, जो संदर्भानुकूल और सुसंगत पाठ सृजन की क्षमता बढ़ाता है। इससे मॉडल एक साथ कई टोकन का अनुमान लगा पाता है, जिससे जनरेशन‑गति और समग्र दक्षता बढ़ती है।
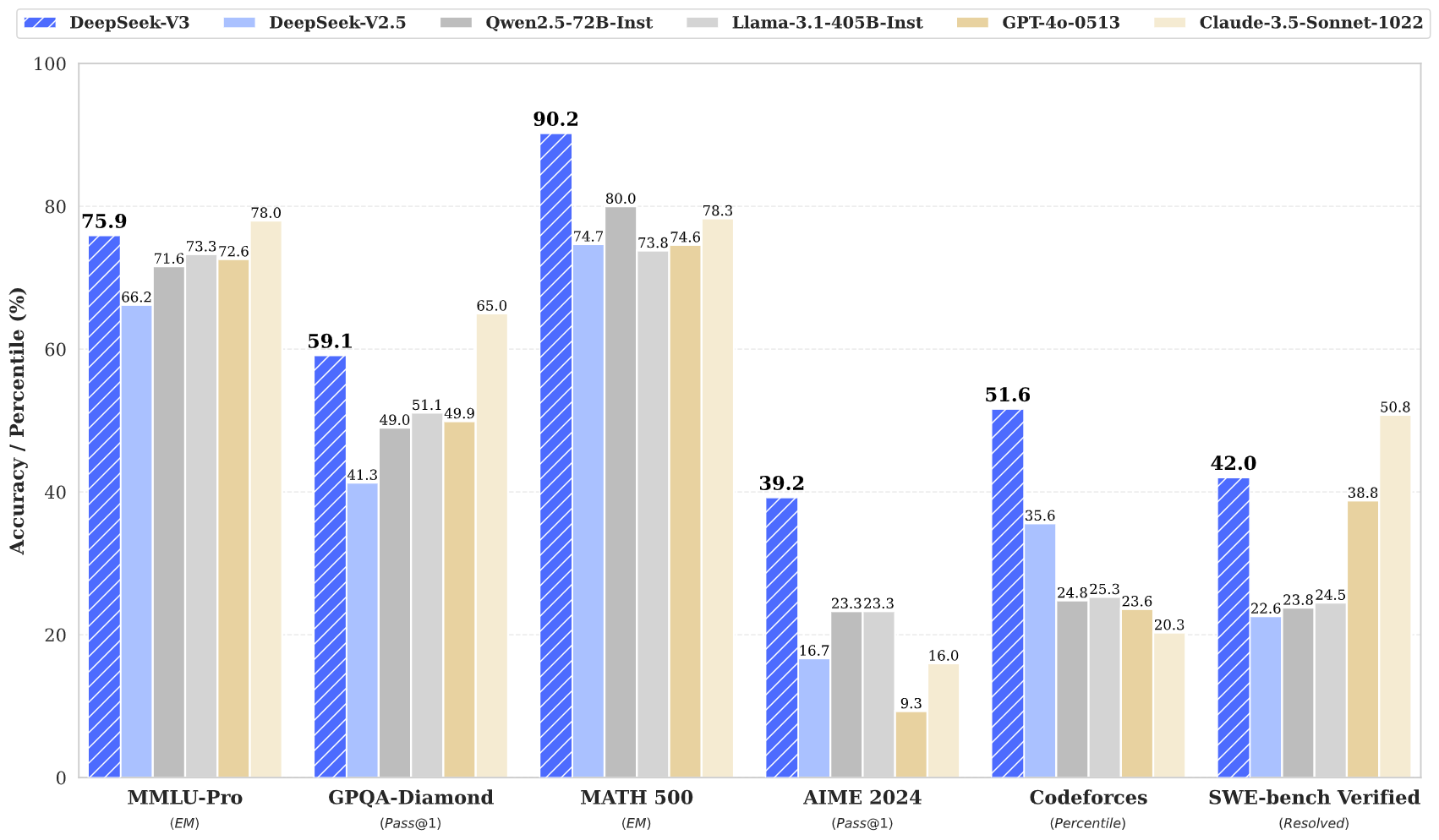
प्रदर्शन सूचकांक
DeepSeek V3 ने कई बेंचमार्क पर उत्कृष्ट प्रदर्शन दिखाया है:
- MMLU: 87.1%
- BBH: 87.5%
- DROP: 89.0%
- HumanEval: 65.2%
- MBPP: 75.4%
- GSM8K: 89.3%
ये आँकड़े दर्शाते हैं कि DeepSeek V3 न केवल GPT‑4 और Claude 3.5 जैसे अग्रणी क्लोज्ड‑सोर्स मॉडलों से प्रतिस्पर्धा करता है, बल्कि कई बार उन्हें पीछे भी छोड़ देता है—विशेषकर जटिल तर्क‑वितर्क और कोडिंग कार्यों में।
प्रशिक्षण दक्षता
DeepSeek V3 का प्रशिक्षण उल्लेखनीय दक्षता के साथ सम्पन्न हुआ:
- कुल प्रशिक्षण लागत: लगभग $5.6 मिलियन
- प्रशिक्षण अवधि: 57 दिन
- आवश्यक GPU घंटे: 2.788 मिलियन H800 GPU घंटे
यह किफायती दृष्टिकोण दिखाता है कि कैसे नवाचारी आर्किटेक्चर पारंपरिक मॉडलों की तुलना में बड़े पैमाने पर संसाधन‑बचत करा सकता है।
संदर्भ विंडो और गति

DeepSeek V3 128,000 टोकन की प्रभावशाली संदर्भ‑विंडो का समर्थन करता है, जिससे लंबी सामग्री और जटिल कार्यों का प्रभावी ढंग से निपटारा संभव होता है। साथ ही, यह अधिकतम प्रति सेकंड 90 टोकन की जनरेशन‑गति देता है, जो इसे उपलब्ध सबसे तेज मॉडलों में शामिल करती है।
निष्कर्ष
संक्षेप में, DeepSeek V3 ओपन‑सोर्स AI प्रौद्योगिकी में एक क्रांतिकारी प्रगति है। इसकी नवाचारी आर्किटेक्चर—MoE और MLA—प्रभावी प्रशिक्षण रणनीतियों और उत्कृष्ट प्रदर्शन सूचकों के साथ मिलकर इसे अत्यधिक प्रतिस्पर्धी बनाते हैं। शक्तिशाली और सुलभ AI समाधानों की बढ़ती माँग के परिप्रेक्ष्य में, DeepSeek V3 AI प्रौद्योगिकी के लोकतंत्रीकरण का नेतृत्व करने के लिए उपयुक्त स्थिति में है।
DeepSeek V3 ओपन‑सोर्स AI विकास में एक महत्वपूर्ण मील का पत्थर है—अत्याधुनिक आर्किटेक्चर और असाधारण दक्षता का संयोजन। इसके प्रदर्शन‑सूचक और नवाचार यह सिद्ध करते हैं कि उच्च‑गुणवत्ता वाले मॉडल पारंपरिक लागत के एक हिस्से में विकसित किए जा सकते हैं, जिससे उन्नत AI तकनीक व्यापक समुदाय के लिए अधिक सुलभ बनती है।