استكشاف الابتكارات التقنية في DeepSeek V3
January 7, 2025
استكشاف الابتكارات التقنية في DeepSeek V3
أثبت DeepSeek V3 نفسه كلاعب بارز بين نماذج الذكاء الاصطناعي مفتوحة المصدر، حيث يجمع بين الابتكار والكفاءة بشكل لافت. ورغم امتلاكه 671 مليار باراميتر، فإنه يفعّل فقط 37 مليارًا لكل رمز، ما يحقق أداءً عاليًا مع تقليل استهلاك الموارد. في هذه التدوينة نستعرض أبرز الابتكارات التقنية التي تميز DeepSeek V3 عن منافسيه.
الميزات التقنية الأساسية
بنية Mixture‑of‑Experts (MoE)
يكمن في قلب DeepSeek V3 تصميم Mixture‑of‑Experts (MoE) المتقدم، والذي يتيح استخدام عدة شبكات صغيرة متخصصة بحسب المهمة تعمل بتعاون. عند ورود الاستعلام، تحدد شبكة التوجيه (gating) الخبراء الذين يجب تفعيلهم، لضمان تشغيل المكونات الضرورية فقط لكل مهمة. هذا التفعيل الانتقائي يعزز الكفاءة والأداء بشكل كبير.
آلية الانتباه الكامن متعدد الرؤوس (MLA)
يعتمد DeepSeek V3 على Multi‑head Latent Attention (MLA) لتعزيز فهم السياق واستخلاص المعلومات. لا تحافظ هذه المقاربة على أداء عالٍ فحسب، بل تقلل أيضًا من استخدام الذاكرة أثناء الاستدلال عبر تقنيات ضغط منخفضة الرتبة. ونتيجة لذلك، يستطيع النموذج معالجة الاستعلامات المعقدة بكفاءة دون المساس بالدقة.
موازنة الأحمال دون خسارة مساعدة
من بين الابتكارات اللافتة في DeepSeek V3 استراتيجيته في موازنة الأحمال دون الاعتماد على خسارة مساعدة. فالأساليب التقليدية قد تؤثر سلبًا على أداء النموذج، بينما يقلل هذا النهج المبتكر من تلك التأثيرات، ما يقود إلى تدريب أكثر استقرارًا وكفاءة.
هدف التنبؤ متعدد الرموز
يقدم DeepSeek V3 هدف تدريب للتنبؤ متعدد الرموز يعزز قدرته على توليد نص مترابط وملائم للسياق. إذ يمكنه التنبؤ بعدة رموز في الوقت نفسه، ما يحسن سرعة التوليد والكفاءة العامة.
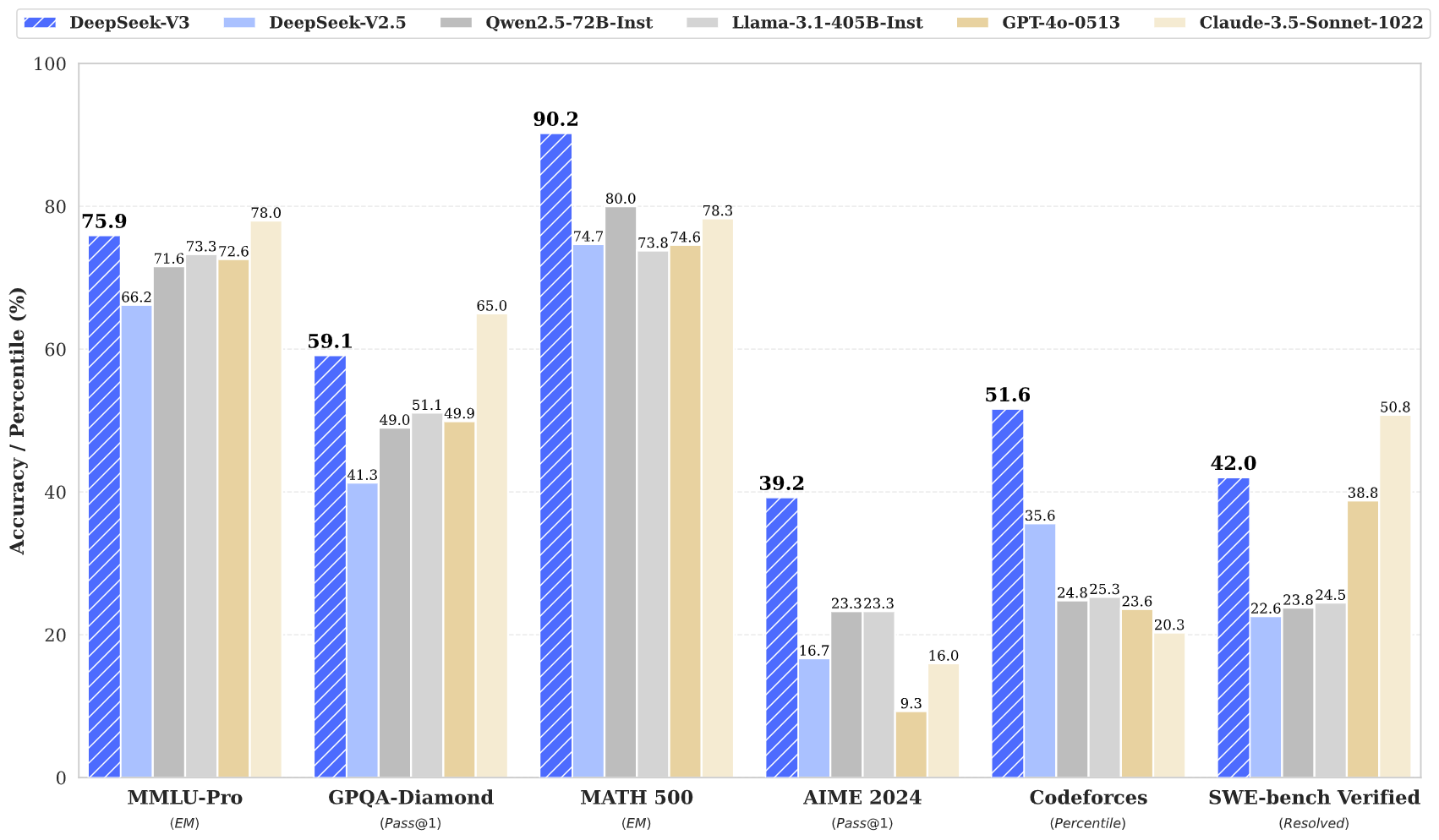
مؤشرات الأداء
أظهر DeepSeek V3 أداءً مميزًا عبر عدة معايير قياس:
- MMLU: 87.1%
- BBH: 87.5%
- DROP: 89.0%
- HumanEval: 65.2%
- MBPP: 75.4%
- GSM8K: 89.3%
تشير هذه النتائج إلى أن DeepSeek V3 لا ينافس النماذج المغلقة الرائدة مثل GPT‑4 وClaude 3.5 فحسب، بل يتفوق عليها أحيانًا، خاصة في مهام الاستدلال المعقد والبرمجة.
كفاءة التدريب
تم تدريب DeepSeek V3 بكفاءة لافتة:
- التكلفة الإجمالية للتدريب: نحو 5.6 مليون دولار
- مدة التدريب: 57 يومًا
- ساعات GPU المطلوبة: 2.788 مليون ساعة GPU من نوع H800
تبرز هذه المقاربة الاقتصادية كيف يمكن للهندسة المبتكرة تحقيق وفورات كبيرة مقارنة بالنماذج التقليدية التي غالبًا ما تحتاج موارد أكبر بكثير.
نافذة السياق والسرعة

يدعم DeepSeek V3 نافذة سياق بحجم 128,000 رمز، ما يمكّنه من التعامل بفاعلية مع المحتوى المطوّل والمهام المعقدة. كما يصل إلى سرعة توليد تصل إلى 90 رمزًا في الثانية، ليكون من أسرع النماذج المتاحة حاليًا.
الخلاصة
باختصار، يمثل DeepSeek V3 قفزة نوعية في تقنيات الذكاء الاصطناعي مفتوح المصدر. فهندسته المبتكرة — MoE وMLA — إلى جانب استراتيجيات التدريب الفعالة ومؤشرات الأداء القوية، تجعله منافسًا بارزًا. ومع تزايد الطلب على حلول ذكاء اصطناعي قوية ومتاحة، يتمتع DeepSeek V3 بموقع مثالي لقيادة ديمقراطية تقنيات الذكاء الاصطناعي.
يمثل DeepSeek V3 علامة فارقة في تطوير الذكاء الاصطناعي مفتوح المصدر، إذ يجمع بين هندسة متقدمة وكفاءة ملحوظة. وتُظهر مؤشراته وابتكاراته أن بناء نماذج عالية الجودة ممكن بتكلفة أقل بكثير من المعتاد، ما يجعل تقنيات الذكاء الاصطناعي المتقدمة أكثر إتاحة للمجتمع.